

2 est toujours accessible, où que vous soyez… jusqu’à ce que vous ne le captiez plus.
- Peut-être que vous avez un long vol à faire et que vous avez besoin d’un peu de lecture
- peut-être que vous voulez juste sauvegarder un site web pour le garder en lieu sûr
Quelle que soit votre raison, voici comment vous pouvez télécharger à peu près tout ce que vous rencontrez sur 2 avec des outils uniquement gratuits.
Pour enregistrer rapidement une page Web
Vous ne le savez peut-être pas, mais votre 2 2 peut enregistrer des pages Web et d’autres éléments.
Dans Chrome
- Cliquez avec le bouton droit de la souris sur n’importe quelle page
- Choisissez Enregistrer sous pour enregistrer la page Web sur votre disque dur
- Vous obtiendrez tout le texte et la plupart des images, mais pas de médias intégrés comme les vidéos
Le processus est similaire avec Firefox
- Cliquez à nouveau sur le bouton droit de la souris sur une zone vide de la page
- Choisissez Enregistrer sous dans le menu qui s’affiche
- Donnez un nom à votre page
En dehors des vidéos en streaming, de l’audio ou des éléments interactifs compliqués, vous devriez avoir un rendu fac-similé de cette page web sur votre système local.
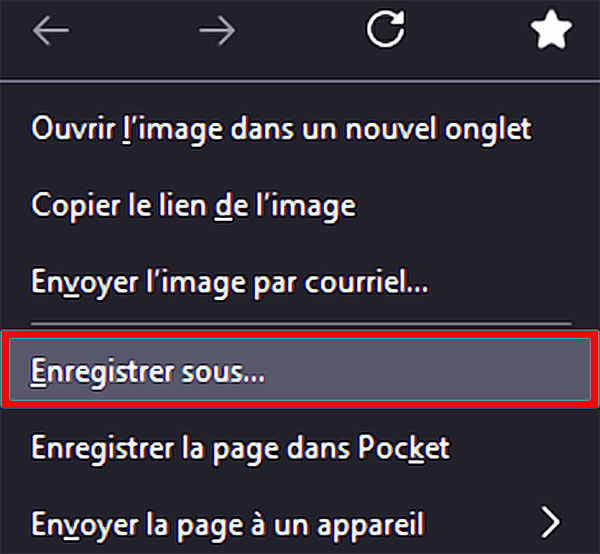
Dans Safari
- Ouvrez une page
- Choisissez Fichier et Enregistrer sous
- Donnez un nom à votre nouveau fichier
- Assurez-vous que le format « Web Archive » est sélectionné
- Et vous avez une copie conforme du site sur lequel vous étiez
Attention : même les publicités et les codes 2 sont copiés, vous aurez une copie conforme du site hors-ligne. Par contre, les médias intégrés sont là aussi oubliés.
Ces outils de sauvegarde sont pratiques mais pas très complets : ils ont été conçus à une époque plus simple où les pages Web étaient statiques, comme des blocs simples de textes et d’images affichés dans le 2.
L’option est pratique, mais vous remarquerez sûrement des éléments manquants en utilisant cette méthode.
➤ A noter
Le fichier enregistré sera au format .html.
- Vous pouvez ouvrir et modifier les fichiers HTML avec divers éditeurs de code source et applications de développement Web.
- Microsoft Visual Studio Code (multiplateforme) est un éditeur de code source utile
- Adobe Dreamweaver (multiplateforme) est une application de développement Web populaire.
- Le langage HTML étant enregistré en texte brut, vous pouvez également ouvrir et modifier les fichiers HTML avec un éditeur de texte de base, tel que Microsoft Notepad (Windows)
- ou Apple TextEdit (Mac), même si ces éditeurs de texte ne disposent pas des fonctionnalités incluses dans les éditeurs de code source et les applications de développement Web qui facilitent le travail des développeurs.
- Vous pouvez prévisualiser une page Web HTML en l’ouvrant avec un 2 Web, tel que Google 2 (multiplateforme), Microsoft Edge (multiplateforme), Mozilla 2 (multiplateforme) ou Apple 2 (Mac et iOS).
Pour sauvegarder une page Web avec ses compléments
Les services de lecture hors-ligne
Quelques services permettent d’obtenir des copies de pages web même en étant hors-ligne :
Ils vous donneront des pages Web sous une forme simplifiée, mais n’aspirent pas une page dans son intégralité.
Dans le même ordre d’idées, Nanonets se veut un outil gratuit de récupération de données sur le Web en convertissant un site Web en texte.
Il utilise un outil de scraping web pour convertir n’importe quelle page web en texte éditable en 3 étapes simples.
- Extrayez des images
- des tableaux
- du texte
- et bien plus encore grâce à cet outil gratuit de récupération de données Web
L’inconvénient, c’est qu’il faut avoir internet puisque vous devez vous rendre sur le site, y implanter l’URL et attendre la conversion.
Les aspirateurs de sites web
Un VPN protege votre vie privee en ligne et securise vos donnees sur les reseaux publics (Wi-Fi gratuit, hotspot, etc.). Si vous cherchez un VPN sans vous ruiner, ProtonVPN a une offre gratuite illimitee (pas de limite de data, pas de carte bancaire).
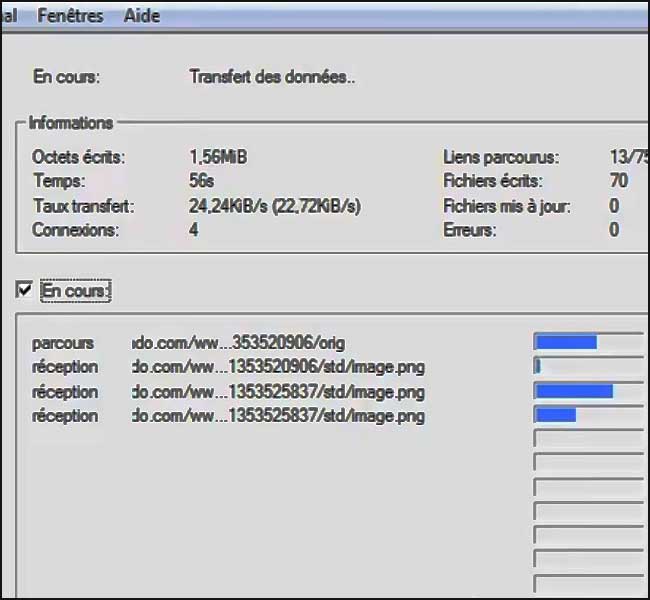
L’un des outils les plus anciens et les plus connus pour un travail d’aspiration complet est HTTrack pour Windows, qui crée plus ou moins le cache complet d’un site sur votre disque local.
C’est comme si vous consultiez le site lui-même, mais tout en étant hors ligne :
- y compris les images
- les polices
- et les liens vers les pages du même domaine
Vos 2 peuvent être catégorisés et couvrir plusieurs URL à l’intérieur d’un même projet.
Alternative pour Firefox : Web Scraper
Automatisez l’extraction de données en 20 minutes. Webscraper.io est conçu pour une utilisation régulière et programmée afin d’extraire de grandes quantités de données et de les intégrer facilement à d’autres systèmes.
La version logicielle est payante mais si vous vous contentez du plugin Firefox, c’est gratuit. Mode d’emploi :
- Configurez le scraper en pointant et en cliquant sur les éléments.
- Aucun codage n’est nécessaire.
- Interface pointer-cliquer.
- Extrait des données de sites web dynamiques.
Web Scraper extrait les données à partir de sites comportant plusieurs niveaux de navigation.
ParseHub
Parsehub est un outil de scraping web qui met l’accent sur la facilité d’utilisation. Il permet aux utilisateurs de collecter des données à partir de n’importe quelle page web JavaScript ou Ajax.
- Ils peuvent effectuer des recherches dans des formulaires
- ouvrir des menus déroulants
- se connecter à des sites web
- cliquer sur des cartes
- et gérer des sites avec un défilement infini, des onglets et des fenêtres contextuelles pour récupérer des données
Les données peuvent être collectées sans qu’il soit nécessaire de coder, car l’outil s’appuie sur l’apprentissage automatique pour comprendre la hiérarchie des éléments.
Pour commencer, les utilisateurs doivent d’abord télécharger l’application de bureau et choisir un site dont ils veulent récupérer les données. Il est également possible de sélectionner des données sur plusieurs pages à l’aide de simples clics et d’interagir avec AJAX, des formulaires, des listes déroulantes, etc.
Ils peuvent ensuite télécharger ou accéder aux résultats via JSON, Excel et API. La solution est basée sur le cloud et fait appel à plusieurs proxy lors de l’exploration du web. Les utilisateurs peuvent même planifier des tâches de collecte de données et utiliser des expressions régulières.
Son prix est de 189 $, mais si vous contentez de 200 pages d’extraction en 40 minutes, c’est gratuit.
Une autre option est Cyotek WebCopy, toujours pour Windows
Son fonctionnement est très similaire, rampant autour d’un site et téléchargeant absolument tout ce qui s’y trouve, y compris les images et les vidéos (tant qu’elles sont hébergées sur le site et qu’elles ne sont pas diffusées en continu depuis un autre endroit).
C’est encore plus complet et convivial que HTTrack, mais ils valent tous les deux la peine d’être découverts.
Si vous êtes du côté de macOS, essayez SiteSucker
Il vous coûtera 5 euros, mais il récupère :
- le texte
- les images
- les feuilles de style et plus encore
- le tout enregistré dans son propre dossier localisé
Il peut même mettre en pause et reprendre les 2.
➽ Aspirateur de site internet SiteSucker :
ProtonVPN vs NordVPN : lequel choisir ?
Un VPN chiffre votre connexion et masque votre adresse IP : indispensable pour proteger votre vie privee, eviter le pistage des FAI et acceder aux contenus bloques dans votre pays. Voici les deux references que je recommande.
| ProtonVPN | NordVPN |
|---|---|
| Open source (code audite) | 5 000+ serveurs dans 60 pays |
| Base en Suisse (lois RGPD strictes) | Base au Panama (aucune conservation de logs) |
| Version gratuite illimitee (sans CB) | Essai 30 jours satisfait ou rembourse |
| Ecosysteme Proton (Mail, Drive, Pass) | Threat Protection (bloqueur pubs integre) |
| Essayer ProtonVPN → | Essayer NordVPN → |
Extraire les images
Les applications que nous venons de mentionner extraient tout d’un site particulier, y compris les images et les vidéos hébergées sur le site, mais il peut y avoir des moments où vous voulez juste prendre une image ou deux sans passer en revue une page HTML entière avec tous ses éléments.
Bien sûr, il y a l’option habituelle de clic droit et de sauvegarde, mais elle n’est pas toujours disponible : elle ne fonctionne pas pour une image cachée en arrière-plan ou intégrée à la feuille de style.
Image Downloader est l’un des meilleurs outils que nous ayons trouvé pour cela
Cliquez sur l’icône d’extension et vous obtenez une liste de toutes les images intégrées à une page, avec les résolutions originales.
En un clic, vous les téléchargez toutes ou vous pouvez les ouvrir dans des onglets séparés et les télécharger individuellement.
Du côté de Firefox, vous avez l’extension Download all images
- Ouvrez une page
- Cliquez sur l’icône d’extension
- Tout est compressé et sauvegardé sur votre disque dur dans un fichier zip
Décompressez l’archive et vous obtenez toutes les images du site, même s’il peut en oublier contrairement à Gallerify qui reconnaît les images cachées et les images de fond.
Pour Safari, il n’y a pas vraiment de téléchargeur d’images équivalent
…même si Save Images travaille sur un appareil iOS (le soft date de 2014).
Sur Mac, le plus simple est d’installer 2 ou 2 pour télécharger toutes les images d’un site, et d’utiliser les extensions disponibles sur ces navigateurs.
Aspirer les vidéos et audios
Ce que ces aspirateurs ne font pas, la plupart du temps, c’est les vidéos et les audios intégrés qui sont conçus pour être visionnés en ligne et non sauvegardés sur disque (par exemple les flux 2 et Spotify).
Une grande partie de ce matériel est protégée par le droit d’auteur, vous courez donc le risque d’enfreindre les lois de votre pays si vous tentez de percer ces systèmes.
Si vous devez absolument obtenir ce contenu vidéo et audio, certaines extensions de navigateur peuvent vous aider.
- Chrome Audio Capture, comme son nom l’indique, capture l’audio dans n’importe quel onglet 2. Vous n’avez qu’à choisir votre format, puis démarrer et arrêter l’enregistrement.
- Sur 2, Audio Downloader Prime est une extension plus sophistiquée qui permet d’identifier les éléments audio individuels d’une page. Elles les télécharge ensuite individuellement.
Pour les téléchargements vidéo, le logiciel de bureau est souvent votre meilleur choix
- 4K Video Downloader fonctionne sur certains sites de streaming vidéo les plus populaires, et se décline dans une version pour Windows et MacOS. Il reste gratuit pour un usage basique.
- L’extension pour 2 IM Integration Module permet également de télécharger les vidéos qui s’affichent sur une page web.
Il existe pas mal d’autres options, mais beaucoup ne sont pas fiables ou frauduleuses :
- elles essayent d’installer quelque chose de plus avec le programme principal
- de mettre un filigrane sur vos clips
- de modifier la page d’accueil de votre 2
- ou de demander des détails personnels avant de procéder au téléchargement

- Rappelez-vous que des gens comme 2 sont très désireux de s’attaquer à ces outils illicites et que les fabricants de logiciels malveillants sont très désireux d’en tirer de l’argent, alors soyez prudents quant aux logiciels que vous utilisez pour ce travail.
- Pensez également à utiliser un VPN avant de télécharger quelque chose d’illégal sur votre ordinateur, un VPN maquillera votre adresse IP, vous rendra anonyme et chiffrera votre connexion pour éviter son piratage
Personnellement nous utilisons NordVPN parce qu’il est no-log (sans enregistrer aucun historique).
⇒ Cliquez pour lire :
Un extracteur de liens pour lister tous les liens d’une page webRedaction web & SEO Vous avez un blog ou un site web ? Je propose mes services de redaction web : creation et mise a jour d'articles optimises SEO, maintenance de blog, audits de contenu, refonte editoriale. Si vous cherchez quelqu'un pour s'occuper de votre contenu (articles, mises a jour, strategie editoriale), contactez-moi, on en discute. J'utilise Semrush pour l'audit SEO et le suivi des positions de mes sites (lien affilie). |

C’est plus simple en ligne de commande :
exemple :
wget -e robots=off -m -r -l 10 -U « Mozilla/440.0 » https://forumamontres.forumactif.com/
L’autre point fort de ScrapingBee est la gestion des proxy. De nombreux sites Web limitent le nombre d’adresses IP sur leurs pages. Disons qu’un site Web autorise 10 requêtes par jour et par adresse IP. Si vous devez effectuer 100 000 requêtes en une seule journée, vous aurez besoin de 10 000 proxys uniques. C’est beaucoup. En général, les fournisseurs de proxy facturent environ un à trois dollars par adresse IP unique et par mois. La facture peut exploser très rapidement.
WebAutomation vous aide à extraire des données instantanément de n’importe quel site Web en quelques minutes, sans codage, grâce à des extracteurs prêts à l’emploi.
Cet extracteur en un clic vous permet d’extraire instantanément des données de plus de 400 sites Web populaires tels que Amazon, Google Maps, eBay, Airbnb, Yelp et bien d’autres !
Le web scraping est une compétence utilisée pour extraire des données de sites web. Ces données peuvent être utilisées pour des études de marché, des comparaisons de prix, des projets de science des données, et plus encore. Il s’agit sans aucun doute de l’une des compétences importantes que vous devez maîtriser en tant que data scientist.
Scraper API est conçu pour simplifier le scraping web. Cet outil proxy API est capable de gérer des proxys, des navigateurs Web et des CAPTCHAs.
Il prend en charge les langages de programmation populaires tels que Bash, Node, Python, Ruby, Java et PHP.
ParseHub est un puissant outil de scraping web qui vous aide à extraire des données en cliquant sur les données dont vous avez besoin.
Pour ce faire, vous devez d’abord télécharger son application de bureau. Une fois l’application installée, ouvrez-la et choisissez un site sur lequel vous souhaitez extraire des données. Cliquez ensuite sur les données cibles pour les extraire. Après cela, les données seront collectées par leurs serveurs et téléchargées dans un format JSON, Excel, API, ou tout autre format que vous avez choisi.
Parmi les fonctions avancées que vous pouvez réaliser avec Parsehub, citons l’obtention de données à partir de plusieurs pages, l’interaction avec AJAX, les formulaires, les listes déroulantes, etc.
HipSocial vous permet de gratter le web pour trouver du contenu intéressant afin de le publier facilement sur les réseaux sociaux. Vous pouvez extraire des données de sites ciblés et les publier directement à partir de l’outil sur des plateformes de réseaux sociaux populaires intégrées.
L’outil comprend NinjaSEO Bot – une extension Chrome bot – qui vous permet d’extraire de grands volumes de données sans aucune programmation. Outre le contenu textuel, vous pouvez récupérer des images pertinentes pour votre marque ou celle de votre client.
HipSocial offre également une fonction d’écoute sociale pour mesurer la performance de vos activités de communication sur les réseaux sociaux ainsi qu’un outil d’analyse des médias sociaux pour évaluer ce qui intéresse vos followers.
HipSocial offre un « prix unique pour 50 applications » à partir de 14,99 $ / mois (cloud) à 74,95 $ / mois (entreprise).
L’extraction de données de sites Web implique généralement l’apprentissage d’un langage de programmation comme Python et de bibliothèques telles que Selenium ou Scrapy ; cependant, même les personnes qui ne savent pas coder peuvent extraire des sites Web.
Apify vous permet aussi de transformer n’importe quel site Web en une API. Il peut vous aider à effectuer du web scraping, de l’automatisation web (automatisation des flux de travail manuels sur le web, comme le remplissage de formulaires ou le téléchargement de fichiers) et de l’intégration web (connexion de divers services web et API).
Parmi les produits sympas qu’il propose, citons actors (plateforme informatique qui facilite le développement, l’exécution et le partage de programmes en nuage sans serveur) et proxy (cache l’origine de vos racleurs Web). En outre, comme les autres outils cités, vous pouvez exporter les données extraites vers des formats tels que CSV, Excel ou JSON.
Les extensions de navigateur Web peuvent constituer un moyen efficace d’extraire des données d’un site Web. L’idéal est d’extraire des données bien formées, par exemple un tableau ou une liste d’éléments sur une page. Certaines extensions, comme DataMiner, proposent des recettes de scraping prêtes à l’emploi pour des sites Web populaires comme Amazon, Ebay, etc.
Les outils de scraping Web sont spécifiquement développés pour extraire des informations des sites Web. Ils sont également connus sous le nom d’outils de récolte Web ou d’outils d’extraction de données Web.
Ces outils sont utiles à toute personne qui tente de collecter des données sous une forme ou une autre à partir d’Internet. Le Web Scraping est la nouvelle technique de saisie de données qui ne nécessite pas de saisie répétitive ou de copier-coller.
Octoparse rend le scraping web facile pour tout le monde. Vous pouvez rapidement extraire des données Web sans coder. Il vous suffit de pointer, de cliquer et d’extraire !
Cet outil divise l’ensemble du processus de scraping en trois étapes. Tout d’abord, vous devez saisir l’URL du site Web dont vous souhaitez extraire des données. Ensuite, vous devez cliquer sur les données cibles que vous souhaitez extraire.
Enfin, il suffit de lancer l’extraction et, en quelques minutes, les données seront prêtes à être utilisées. Les données que vous extrayez peuvent être stockées dans un fichier CSV, Excel, API ou une base de données. Choisissez l’option qui vous convient le mieux.
Les outils de raclage de sites Web peuvent vous aider à vous tenir au courant de l’évolution de votre entreprise ou de votre secteur d’activité au cours des six prochains mois, ce qui constitue un outil puissant pour les études de marché.
Ces outils peuvent récupérer des données auprès de plusieurs fournisseurs d’analyses de données et de sociétés d’études de marché et les regrouper en un seul endroit pour faciliter la consultation et l’analyse.
Les outils de scraping Web comme ScreamingFrog ou ScrapeBox sont parfaits pour extraire des données du Web, et de Google en particulier. Selon votre cas d’utilisation, comme le SEO, la recherche de mots-clés ou la recherche de liens brisés, c’est peut-être la chose la plus facile à utiliser.
D’autres logiciels comme ParseHub sont également très utiles pour les personnes qui n’ont pas de connaissances en codage. Il s’agit d’applications de bureau qui permettent d’extraire facilement des données du Web. Vous créez des instructions sur l’application, comme la sélection de l’élément dont vous avez besoin, le défilement, etc.
Ces outils peuvent également être utilisés pour extraire des données telles que les emails et les numéros de téléphone de divers sites web, ce qui permet de disposer d’une liste de fournisseurs, de fabricants et d’autres personnes présentant un intérêt pour votre activité ou votre entreprise, ainsi que de leurs adresses de contact respectives.
Zyte (anciennement Scrapinghub) est un outil d’extraction de données basé sur le cloud qui aide des milliers de développeurs à récupérer des données précieuses. Zyte utilise Crawlera, un rotateur de proxy intelligent qui permet de contourner les contre-mesures des robots pour explorer facilement des sites volumineux ou protégés par des robots.
Zyte convertit la page Web entière en contenu organisé (25 euros par mois).
ParseHub est conçu pour explorer un ou plusieurs sites Web et prend en charge JavaScript, AJAX, les sessions, les cookies et les redirections. L’application utilise une technologie d’apprentissage automatique pour reconnaître les documents les plus compliqués sur le web et génère le fichier de sortie en fonction du format de données requis.
ParseHub, outre l’application web, est également disponible en tant qu’application de bureau gratuite pour Windows, macOS et Linux qui propose un plan gratuit de base couvrant cinq projets de crawl. Ce service propose un plan premium pour 89 dollars par mois avec une prise en charge de 20 projets et 10 000 pages web par crawl.
À l’aide d’un outil de scraping web, on peut également télécharger des solutions pour une lecture ou un stockage hors ligne en collectant des données sur plusieurs sites (notamment StackOverflow et d’autres sites de questions-réponses).
Cela réduit la dépendance à l’égard des connexions Internet actives, car les ressources sont facilement accessibles malgré la disponibilité d’un accès internet.
Ces outils permettent également d’extraire sans effort des données sur la base de différents filtres appliqués et de récupérer des données de manière efficace sans recherche manuelle.
ScrapingBot est une excellente API de scraping web pour les développeurs web qui ont besoin de récupérer des données à partir d’une URL. Elle fonctionne particulièrement bien sur les pages de produits où elle collecte tout ce dont vous avez besoin (image, titre du produit, prix du produit, description du produit, stock, frais de livraison, etc…). C’est un excellent outil pour ceux qui ont besoin de collecter des données commerciales ou simplement d’agréger des données de produits et de les garder exactes.
ScrapingBot propose également diverses API spécialisées telles que l’immobilier, les résultats de recherche Google ou la collecte de données sur les réseaux sociaux (LinkedIn, TikTok, Instagram, Facebook, Twitter).
Scraper est une extension Chrome dont les fonctionnalités d’extraction de données sont limitées, mais qui permet d’effectuer des recherches sur internet et d’exporter des données vers des tableurs Google. Cet outil est destiné aux débutants et aux experts qui peuvent facilement copier des données dans le presse-papiers ou les stocker dans des feuilles de calcul en utilisant OAuth.
Scraper est un outil gratuit qui fonctionne directement dans votre navigateur et génère automatiquement de petits XPaths pour définir les URL à explorer. Il ne vous offre pas la facilité du crawling automatique ou robotisé comme Import, Webhose et d’autres, mais c’est aussi un avantage pour les novices car vous n’avez pas besoin de vous attaquer à une configuration compliquée.
Le scraping des pages de résultats de recherche de Google peut être un véritable casse-tête sans la configuration adéquate. L’API SERP de Smartproxy est une excellente solution pour cela. Cette API SERP combine un énorme réseau de proxy, un scraper Web et un analyseur de données.
Il s’agit d’une solution complète qui vous permet d’obtenir des données structurées à partir des principaux moteurs de recherche en envoyant une seule demande d’API réussie à 100 %.
Vous pouvez cibler n’importe quel pays, état ou ville et obtenir des résultats bruts en HTML ou des résultats analysés en JSON. Qu’il s’agisse de vérifier le classement des mots clés et de localiser d’autres paramètres de SEO en temps réel, de récupérer des données payantes et organiques ou de surveiller les prix, les proxys de moteurs de recherche de Smartproxy couvrent tout.
Le web est en train de devenir une incroyable source de données. Il y a de plus en plus de données disponibles en ligne, qu’il s’agisse de contenu généré par les utilisateurs sur les réseaux sociaux et les forums, de sites de commerce électronique, de sites immobiliers ou de médias… De nombreuses entreprises sont construites sur ces données web, ou en dépendent fortement.
Extraire manuellement des données d’un site web et les copier/coller dans une feuille de calcul est un processus long et sujet aux erreurs. Si vous devez extraire des millions de pages, il n’est pas possible de le faire manuellement, vous devez donc l’automatiser.
Bonjour, je cherche à faire un truc différent de ce qui est énoncé au-dessus. Une page web avec un champ de formulaire, renvoi une liste de résultat suivant ce qu’on a mis dans le champ (un code postal). Est-il possible de récupérer l’ensemble des résultats possibles en rejouant le même scenario pour une liste de codes postaux.
C’est une base de données publique qui n’est pas téléchargeables (sur ce que j’ai pu avoir comme information jusqu’à maintenant…) et qui ne propose pas non plus d’API.
Scrapy est un framework open source de scraping web en python. À notre avis, il s’agit d’un excellent point de départ pour extraire des données structurées de sites Web à grande échelle. Il résout de nombreux problèmes courants de manière très élégante :
– Concurrence (Scraping de plusieurs pages en même temps)
– Auto-throttling, afin d’éviter de perturber les sites Web tiers dont vous extrayez les données.
– Format d’exportation flexible, CSV, JSON, XML et backend pour le stockage (Amazon S3, FTP, Google cloud…)
– Rampement automatique
– Pipeline média intégré pour télécharger les images et les ressources
ScrapingBee peut vous aider à la fois avec la gestion du proxy et les navigateurs sans tête. C’est une excellente solution lorsque vous ne voulez pas vous occuper de l’un ou l’autre.
L’utilisation de navigateurs sans tête en production pose de nombreux problèmes. Il est facile d’exécuter une instance de Selenium ou de Puppeteer sur votre ordinateur portable, mais en exécuter des dizaines en production relève d’un autre domaine. Tout d’abord, vous avez besoin de serveurs puissants. Headless Chrome, par exemple, nécessite au moins 1 Go de mémoire vive et un cœur de processeur pour fonctionner correctement.
Si vous avez besoin d’une grande quantité de données provenant du Web pour un cas d’utilisation spécifique, vous pouvez vérifier que l’ensemble de données n’existe pas déjà. Par exemple, disons que vous voulez la liste de tous les sites Web dans le monde utilisant une technologie particulière comme Shopify. Ce serait une tâche énorme que de parcourir l’ensemble du Web ou un annuaire (si un tel annuaire existe) pour obtenir cette liste. Vous pouvez facilement obtenir cette liste en l’achetant à des courtiers en données comme builtwith.com.
Sitechcker propose un robot d’exploration de sites Web basé sur le cloud qui explore votre site en temps réel et fournit une analyse SEO technique. En moyenne, l’outil parcourt jusqu’à 300 pages en 2 minutes, en analysant tous les liens internes et externes, et vous fournit un rapport complet directement sur votre tableau de bord.
Vous pouvez personnaliser les règles et les filtres de l’outil d’exploration à l’aide de paramètres flexibles, en fonction de vos besoins, et obtenir un score fiable qui vous renseigne sur la santé de votre site.
De même, vous serez informé par email de tous les problèmes survenant sur votre site, et vous pourrez également collaborer avec les membres de votre équipe et les entrepreneurs en envoyant un lien partageable vers le projet.
L’objectif de WebScraper est de rendre l’extraction de données web aussi simple que possible. Contrairement à d’autres outils, il s’agit d’une extension disponible sur Chrome et Firefox. Vous pouvez configurer un scraper en pointant et en cliquant simplement sur des éléments.
WebScraper vous permet également d’extraire des données de sites Web dynamiques. Il peut extraire des données de sites comportant plusieurs niveaux de navigation et parcourir un site Web à tous les niveaux (catégories et sous-catégories, pagination, pages de produits). Les données peuvent être exportées vers les formats CSV, XLSX et JSON, et même vers Dropbox.
Import.io offre un constructeur pour former vos propres ensembles de données en important simplement les données d’une page web particulière et en exportant les données vers CSV. Vous pouvez facilement gratter des milliers de pages Web en quelques minutes sans écrire une seule ligne de code et construire plus de 1000 API en fonction de vos besoins.
Import.io utilise une technologie de pointe pour récupérer des millions de données chaque jour, que les entreprises peuvent utiliser pour une somme modique. En plus de l’outil web, il offre également des applications gratuites pour Windows, macOS et Linux pour construire des extracteurs de données et des crawlers, télécharger des données et se synchroniser avec le compte internet.