

L’optimisation des moteurs de recherche (SEO) consiste à créer ou à améliorer des sites Web qui plaisent aux utilisateurs et aux robots des moteurs de recherche.
- Il y a des facteurs techniques à prendre en compte pour les robots
- et des facteurs d’expérience à prendre en compte pour les personnes
Le SEO est souvent un effort de consultation avec les développeurs et les concepteurs responsables de la construction d’un site Web et les rédacteurs responsables du contenu.
Le résultat d’une mise en œuvre correcte des recommandations de SEO sur un site Web est un plus grand nombre d’utilisateurs arrivant des moteurs de recherche (trafic de recherche organique).
Dans cet article, il sera beaucoup question de Google, car il détient environ 92 % des parts de marché des moteurs de recherche dans le monde.
- Un bon classement dans Google
- se traduit généralement par un bon classement dans d’autres moteurs de recherche
- comme Qwant
- Bing
- ou DuckDuckGo
Il peut y avoir quelques différences mineures si vous souhaitez être bien classé dans des moteurs de recherche internationaux comme Yandex (Russie), Baidu (Chine) ou Naver (Corée du Sud).
Quels sont les facteurs importants pour le classement des recherches ?
En commençant par le haut, ils sont classés par ordre de nécessité.
- Accessibilité pour les moteurs de recherche
- Contenu unique
- Liens (internes et externes)
- Concentration sur les mots-clés et les sujets
- Intention de l’utilisateur
- Expérience de l’utilisateur (compatibilité des appareils, vitesse, interface utilisateur)
- Contenu frais
- Taux de clics (CTR)
- Expertise, autorité, fiabilité (EAT)
- Directives des moteurs de recherche (ne pas enfreindre les règles)

SEO et fonctionnement des moteurs de recherche
Robots
Un robot de moteur de recherche est un logiciel qui « explore » les pages Web en suivant les liens.
Le « bot » collecte (ou indexe) le code de la page et les connexions (liens) entre les pages. La structure des mots et du code d’une page donne un contexte aux informations recueillies.
Le SEO nécessite de comprendre la perspective d’un robot de moteur de recherche.
- En d’autres termes, comment un robot d’exploration du Web voit-il l’intégralité d’un site Web ou d’un domaine ?
- Quelles sont les métadonnées présentes sur les pages ?
- Comment les pages sont-elles reliées entre elles ?
Pour aller plus loin, considérez comment un moteur de recherche voit l’ensemble des sites web sur internet.
➽ Les Crawlers
La meilleure façon de comprendre le fonctionnement des crawlers est d’en utiliser un vous-même ! Il existe plusieurs options populaires, qu’il s’agisse de logiciels installés localement :
- Screaming Frog
- Sitebulb
- Xenu’s Link Sleuth
..ou basés sur le cloud :
- Botify
- DeepCrawl
- OnCrawl
De nombreux outils de SEO (Moz, Ahrefs, SEMrush, etc.) utilisent des robots pour parcourir internet et construire leurs bases de données.
Personnes
Google dit : « Faites des pages principalement pour les utilisateurs, pas pour les moteurs de recherche. »
C’est leur principe n°1, et c’est logique. L’empathie est la clé.
- Il est important de tenir compte de l’état d’esprit
- de l’intention
- et de l’expérience globale des internautes lorsqu’ils effectuent des recherches sur internet
Le produit de recherche de Google n’est populaire que parce qu’il offre une expérience de contenu de haute qualité. Si une page n’est pas utile ou agréable pour une personne, elle ne sera pas bien classée dans un moteur de recherche moderne.
C’est à peu près tout ce que vous devez savoir ! (Mais continuez à lire si vous voulez connaître les détails).
Algorithmes
Les moteurs de recherche utilisent des algorithmes propriétaires pour classer les résultats de recherche en fonction de la qualité et de la pertinence de la page de ressource par rapport à la requête de recherche.
Vous pouvez étudier les brevets, les annonces et les avis d’experts, mais Google garde ses algorithmes comme un secret bien gardé.
Les facteurs SEO peuvent être classés en deux grandes catégories :
- les efforts sur page
- et hors page
| Les facteurs hors page sont des signaux externes trouvés sur des sites Web ou des bases de données qui influencent les classements de recherche, comme les liens externes d’autres sites Web, le sentiment ou les données comportementales recueillies. |
| Les facteurs on-page sont les éléments qu’un propriétaire de site Web peut contrôler, comme son propre site Web ou d’autres propriétés comme les annuaires professionnels et les profils sociaux. |
Accessibilité
Avant tout, les moteurs de recherche doivent pouvoir accéder à un site web et à toutes ses pages.
Si un robot d’exploration ne peut pas trouver et indexer une page, celle-ci n’a aucune chance d’être classée dans les résultats de recherche. Il doit être facile de comprendre le contenu d’une page.
Il existe plusieurs façons pour un crawler de moteur de recherche d’avoir des difficultés à accéder à une page ou à la comprendre :
- Robots.txt disallow
- Balises Meta (noindex, nofollow)
- Codes de statut d’erreur (statut non 200)
- Balises canoniques incorrectes
- Contenu non indexable (javascript / flash / vidéo)
- Budget du crawl
- Aucun lien vers une page
➽ Le fichier Robots.txt
Il se trouve à la racine de votre domaine (domain.com/robots.txt). Il indique aux robots (alias bots, web crawlers, spiders) les pages qu’ils peuvent et ne peuvent pas explorer.
Le fait d’interdire une page ne l’exclut pas de l’index d’un moteur de recherche. Les pages interdites peuvent encore apparaître dans les résultats de recherche si elles sont découvertes par d’autres signaux comme les liens.
La plupart des robots suivent ces directives, mais ils n’y sont pas obligés. Les principaux robots des moteurs de recherche, tels que googlebot ou bingbot, devraient toujours suivre ces règles.
Vous pouvez tester si les pages sont accessibles à l’aide de l’outil de test des robots de la Search Console de Google (nécessite un compte Google Search Console).
➽ Une balise meta robots noindex
Elle exclut une page de l’index de recherche.
Cette balise indique à un robot d’exploration Web de ne pas inclure la page dans son index de recherche, de sorte qu’elle ne sera pas affichée dans les résultats de recherche.
Les pages non indexées restent accessibles aux robots d’exploration et transmettent toujours la valeur des liens à travers la page. Selon certaines déclarations récentes des porte-parole de Google, les pages comportant des balises noindex pourraient être explorées moins fréquemment au fil du temps, au point de ne plus être explorées.
➽ Codes d’état
Un code d’état 200 OK indique au serveur que la demande a été acceptée. Une page doit renvoyer ce statut pour qu’un moteur de recherche puisse l’explorer et l’indexer.
- Les autres codes comprennent 3xx (codes de redirection comme 301, 301 et 307)
- 4xx (codes d’erreur comme 404, 410)
- et 5xx (erreurs de serveur comme 500, 503, 504)
Chaque famille de codes d’état comprend plusieurs codes pour des situations légèrement différentes. Ne servez pas un 200 ou un 301 sur une page non trouvée, servez le statut approprié, 404 non trouvé.
➽ Les balises canoniques
Elles indiquent aux robots d’exploration du Web quelle page dupliquée est l’URL correcte à indexer.
Si la balise canonique n’est pas correcte, cela entraînera une confusion pour le robot d’exploration du moteur de recherche.
Les balises canoniques sont des « indices » pour Google, plutôt que des directives, de sorte qu’il peut utiliser d’autres signaux pour choisir une page canonique en cas de confusion.
➽ Contenu non indexable
Si le contenu dépend de processus de rendu côté client (javascript, flash) ou n’est pas sous forme de texte (image, vidéo, audio), les robots d’exploration du Web ont des difficultés à le comprendre.
Les moteurs de recherche modernes, comme Google, peuvent traiter et rendre le javascript, mais il faut une quantité énorme de ressources pour le faire à l’échelle internet.
En raison des ressources nécessaires, le rendu du javascript est effectué en tant que processus distinct, dans une file d’attente hiérarchisée. La page doit être considérée comme une page importante et de haute qualité pour être rendue en priorité.
La manière optimale de servir une page aux robots des moteurs de recherche est de rendre tout le code html côté serveur, avant qu’il atteigne l’ordinateur d’un utilisateur humain ou un robot d’exploration.
➽ Budget de crawl / Taux de crawl
L’exploration de tous les sites Web sur internet est une tâche gigantesque qui nécessite de nombreuses ressources informatiques.
Google doit donc établir des priorités ou un budget pour l’utilisation de ces ressources chaque jour. Les taux d’exploration sont fixés pour chaque site Web en fonction :
- de sa taille
- de sa vitesse
- de sa popularité
- et de la fréquence de ses modifications
Un plus grand nombre de pages peuvent être explorées si elles sont plus rapides à télécharger ou si elles sont très populaires. Google crawlera moins de pages au fil du temps si les pages crawlées sont de mauvaise qualité ou s’il n’est pas utile de les renvoyer dans les résultats de recherche.
Si le robot Google rencontre beaucoup d’erreurs ou de redirections pendant l’exploration, cela peut avoir un impact négatif sur le taux d’exploration.
Lorsqu’un moteur de recherche a des difficultés à explorer un site ou ne consomme que des pages de faible qualité, le site peut sembler de qualité inférieure dans l’ensemble et avoir un effet négatif sur tous les classements du domaine.
➽ Aucun lien vers une page
Le robot d’exploration d’un moteur de recherche ne trouvera pas une page s’il ne trouve pas un lien vers cette page.
Si les liens sont rares ou enfouis profondément dans le site, la page en question risque de ne jamais être trouvée.
Contenu unique
Si la même page ou presque peut être trouvée à une URL différente (la moindre petite différence), elle est considérée comme une page dupliquée.
Les moteurs de recherche identifient le meilleur résultat ou le plus original et filtrent les autres résultats dupliqués. De nombreux contenus dupliqués sont créés sur internet :
- que ce soit intentionnellement (vol, copie et syndication de contenu)
- ou involontairement (configuration du CMS, paramètres du domaine/réseau)
Voici quelques problèmes courants de duplication non intentionnelle :
- Paramètres de requête / codes UTM / codes de suivi
- Différents domaines ou sous-domaines pointant vers les mêmes pages (versions non-www / www)
- Protocole (https / http)
- Structure de l’URL (barre oblique de fin ou pas)
- Capitalisation variable
Les problèmes mentionnés ci-dessus se traduisent par de légères variations d’une URL qui peut néanmoins charger la même page. La meilleure façon de corriger les pages dupliquées est de rediriger vers la version canonique.
La balise canonique est également recommandée ; elle indique au moteur de recherche de consolider la valeur de l’URL canonique.
Google filtre les URL en double ; elles ne sont pas pénalisées. Si les URL dupliquées ne sont pas gérées correctement, la valeur du lien peut être divisée entre différentes variantes de l’URL.
➽ Google est très doué pour déterminer l’éditeur original du contenu
Si l’ensemble de votre site Web est constitué de contenu copié à partir d’autres sources, il vous sera difficile d’obtenir un quelconque classement dans les moteurs de recherche.
- Les moteurs de recherche disposent d’outils permettant d’identifier les quasi-duplications
- comme la copie de courtes sections de texte provenant de diverses sources (shingling)
- ou la reformulation légère d’un contenu existant (spinning)
Les tactiques qui consistent à dupliquer du contenu existant ne fonctionnent pas bien. Créez quelque chose d’unique (et de précieux) si vous voulez gagner du trafic sur les moteurs de recherche.

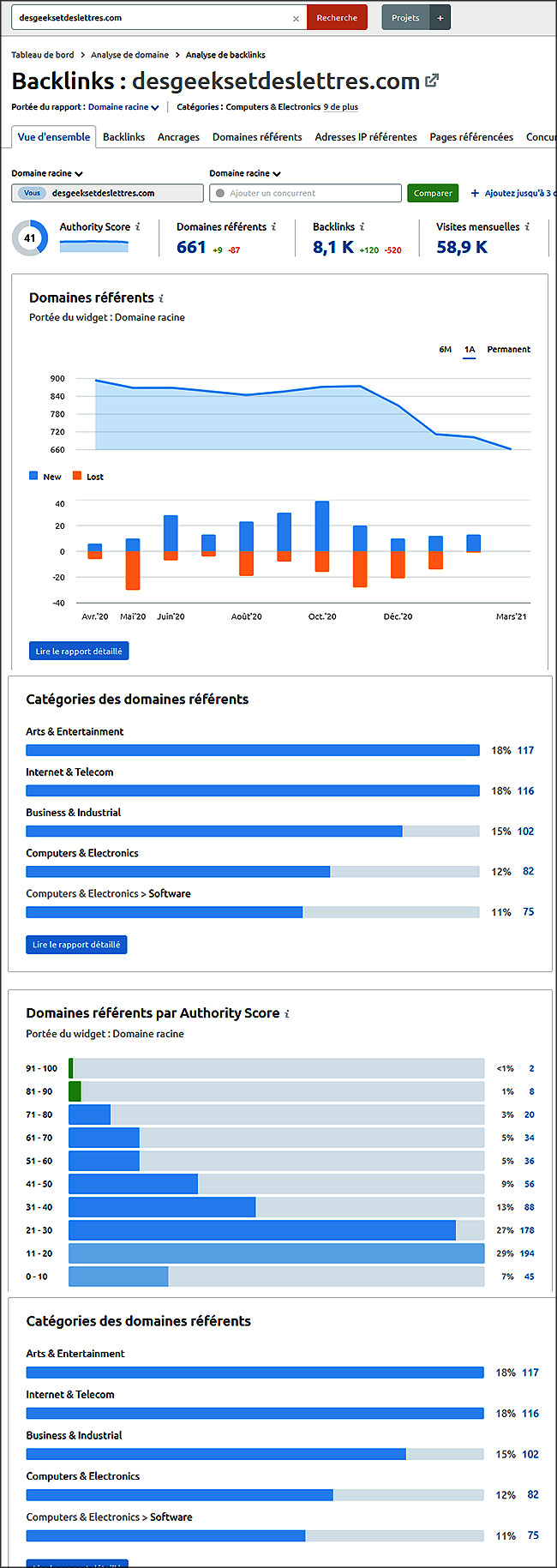
Liens (internes et externes)
Google a changé le jeu des moteurs de recherche en classant les pages en fonction de leur popularité (liens pointant vers elles) plutôt que par des mesures simplistes de l’occurrence des mots clés sur une page.
➽ Qu’est-ce que le Pagerank ?
Larry Page, cofondateur de Google, a mis au point un système de notation appelé PageRank, qui mesure l’importance d’une page Web en fonction du nombre de liens pointant vers elle sur le Web.
Chaque page acquiert une valeur (valeur de la page, valeur de recherche, valeur du lien, jus de lien, autorité de la page) déterminée par la quantité et la qualité des liens pointant vers la page.
La qualité des liens est mesurée par :
- L’autorité de la page de liaison
- La pertinence
- La confiance
- Placement sur la page, contexte
- Texte d’ancrage
- Nombre d’autres liens sur la page
- Nofollow
La valeur des liens est récursive car l’autorité d’une page est largement déterminée par la quantité et la qualité des liens qui pointent vers elle. En d’autres termes, les pages qui font autorité ont d’autres pages qui font autorité qui pointent vers elles.
➽ La pertinence des liens est importante à deux égards
- 1) la pertinence de la page de liaison par rapport à la destination du lien
- 2) le maintien de la pertinence d’une page dans le temps par rapport aux liens qui pointent vers elle
Si le propriétaire d’un site modifie ou supprime radicalement une page, les liens existants qui pointent vers elle perdent toute valeur car la pertinence est oblitérée.
La confiance peut être mesurée :
- par la proximité d’un domaine par rapport à un ensemble de domaines de confiance
- le niveau de méchanceté détecté sur un domaine
- le sentiment des utilisateurs dans les critiques trouvées sur d’autres sites
➽ L’emplacement d’un lien sur une page peut déterminer sa valeur relative
- pied de page = faible
- boîte de liens répétés sur chaque page = faible
- lien contextuel dans un article = élevé
- liste de liens connexes = moyen
- liens dans la navigation principale = aide à indiquer la structure ou l’organisation du site
Le texte d’ancrage est le texte qui est lié. Ces mots-clés aident le moteur de recherche à mieux comprendre le contenu de la page liée.
Le nombre de liens sur la page est important car la valeur de la page est répartie entre tous les liens de la page.
Si une page a une valeur théorique de 6 et comporte trois liens, une valeur de 2 (moins un facteur d’amortissement) circule à travers chaque lien vers la page de destination. Le PageRank est monumentalement plus complexe que cela, mais c’est une façon simple de comprendre le concept de base.
➽ Nofollow est une balise méta qui indique aux moteurs de recherche de ne pas faire confiance au lien
Cela signifie que la valeur du lien ne passera pas par lui.
Google a récemment modifié ses conseils sur le nofollow pour indiquer qu’il est traité comme une « indication » plutôt que comme une directive, il est donc possible que certains liens nofollow soient utilisés pour le classement.
➽ Structure du site (liens internes)
La structure d’un site est définie par la mise en place de liens internes depuis la page d’accueil :
- jusqu’aux pages des rubriques
- pages des articles
- des catégories
- et partout ailleurs
📊 À retenir : Si vous voulez auditer votre site et tracker vos positions, Semrush est l'outil que j'utilise au quotidien (l'offre gratuite est déjà très complète). Auditer mon site avec Semrush
La navigation principale, le pied de page, les liens contextuels, les rubriques, les types de contenu, les archives et la pagination d’un site ont tous un impact sur la structure du site.
La valeur des liens externes peut entrer dans un site à n’importe quelle page, mais c’est souvent la page d’accueil d’un site qui a le plus de liens externes et internes pointant vers elle.
La valeur des liens circule sur l’ensemble d’un site par le biais des liens internes. Il est donc important que les liens internes distribuent la valeur des liens de manière homogène sur l’ensemble du site, en particulier vers les pages de contenu qui peuvent être bien classées dans les SERP.
- Considérez la structure du site comme des « niveaux » ou des clics à partir de la page d’accueil, également appelés profondeur d’exploration.
- Utilisez un robot d’exploration Web pour vérifier la profondeur d’exploration et déterminer si vos pages sont éloignées de la page d’accueil ou d’autres points d’entrée.
Les pages d’un site Web ayant le plus de liens internes seront considérées comme les pages les plus importantes de ce site.
- Assurez-vous que vos pages les plus importantes sont claires.
- Assurez-vous que les pages les plus importantes pour vous sont également les plus importantes pour votre public.
A lire ➽ Comment utiliser les mots-clés dans votre contenu pour le référencement
Concentration sur les mots-clés et les sujets
Les moteurs de recherche doivent comprendre le sujet d’une page
Cela commence par les mots-clés.
Un mot-clé est un mot ou une expression qui représente un concept. Les moteurs de recherche publient les volumes de recherche mensuels sur les mots clés pour aider les créateurs de contenu à comprendre ce que les gens recherchent.
Il est difficile de se classer pour des mots clés à fort volume, mais si vous ne ciblez pas un certain volume de recherche, vous écrirez pour quelque chose que personne ne recherche.
La recherche de mots-clés comprend également une analyse de la concurrence
Vérifiez les pages de résultats des moteurs de recherche pour les mots clés que vous recherchez.
Si vous visez un mot-clé à fort volume et à forte valeur, vous risquez de vous heurter à une concurrence féroce. Sachez que vous allez devoir créer quelque chose de mieux que les pages les mieux classées.
En tant qu’entreprise, vous pensez peut-être vouloir être classé pour un mot clé à fort volume, mais si vous ne comprenez pas l’intention de l’utilisateur dans une requête (voir ci-dessous), vous risquez de déployer beaucoup d’efforts pour attirer des personnes qui n’ont pas besoin ou ne veulent pas de votre solution.
- Utilisez vos recherches pour identifier un mot-clé cible
- Et utilisez des variantes de celui-ci dans vos titres et dans l’ensemble du contenu
Veillez à ce que votre écriture soit naturelle, et non robotique ou répétitive. N’essayez pas de remplir la page avec un langage non pertinent ou non naturel juste pour y glisser des mots clés.
En s’appuyant sur les mots-clés, un sujet englobe plusieurs mots-clés et sous-thèmes
Aux premiers jours des moteurs de recherche, il était important de se concentrer sur un mot clé spécifique pour chaque page, mais avec les progrès du traitement du langage naturel, les moteurs de recherche comprennent mieux le concept d’une page et le sens d’une requête.
Les moteurs de recherche ont analysé d’énormes corpus de textes pour construire des entités afin de comprendre :
- comment les mots et les choses sont connectés
- regroupés
- et liés les uns aux autres
Une page peut désormais être classée pour des centaines ou des milliers de mots clés, même s’ils ne sont pas spécifiquement mentionnés sur la page.
L’un des facteurs qui déterminent le classement d’une page est l’exhaustivité de sa couverture du sujet
Comprenez les sous-thèmes qui sont couverts (ou devraient être couverts) par un sujet et assurez-vous d’avoir la page la plus complète possible.
À l’inverse, une page ne doit pas couvrir une variété de sujets
Une URL doit représenter un seul concept ou sujet (y compris les sous-sujets) afin que la page puisse être comprise comme une ressource ou une réponse à une requête de recherche.
Un moteur de recherche aura du mal à comprendre le contenu d’une page si la même page ou URL couvre de nombreux sujets différents.
Comment effectuer une recherche de mots clés en SEO : Le Guide du Débutant |
Les 25 fonctions les plus puissantes de SEMrush pour améliorer votre classement dans les moteurs de recherche |
Intention de l’utilisateur
Intention explicite et implicite
L’intention de l’utilisateur est l’objectif spécifique qu’un utilisateur a en tête lorsqu’il utilise un moteur de recherche.
L’intention peut être explicite ou implicite.
- Si l’intention est incluse dans la requête, comme « acheter des jeux de société », il s’agit d’une intention explicite ou claire que l’utilisateur veut faire un achat.
- De nombreuses requêtes ont une intention implicite. Considérez la requête : « tache de vin rouge ». Il semble évident que quelqu’un veut des informations sur le nettoyage d’une tache de vin rouge. Il s’agit d’une intention implicite et vous pouvez le voir dans les résultats de recherche.
L’apprentissage automatique informe l’intention de l’utilisateur
Google utilise l’apprentissage automatique sur de grands ensembles de données pour comprendre l’intention implicite à grande échelle. En suivant les types de résultats sur lesquels les internautes cliquent le plus souvent, il peut prédire les intentions des utilisateurs qui ne sont pas explicitement exprimées.
Pour comprendre comment Google interprète les intentions des utilisateurs, il suffit de consulter les résultats de la recherche.
- Par exemple, si vous recherchez « jeux de société », vous verrez apparaître des magasins qui vendent des jeux de société, car cette requête présente une forte intention d’achat.
- Vous remarquerez qu’il existe des listes des « meilleurs jeux de société », car cette requête implique également que l’utilisateur n’a pas encore décidé quel jeu acheter.
Testez des variantes de requêtes et critiquez les résultats pour mieux comprendre les différentes intentions des utilisateurs. Si vous voulez que votre page Web soit classée pour une requête, vous devez vous aligner sur les intentions principales de l’utilisateur.
Faire, Savoir, Aller
Dans ses Directives pour les évaluateurs de qualité, Google fait référence aux intentions les plus élémentaires des utilisateurs sous la forme « Do, Know, Go » :
- Faire : Transactionnel (vouloir faire ou acheter quelque chose)
- Savoir : Informatif (qu’est-ce que c’est ? ou comment ça marche ?)
- Aller : Navigation (où se trouve le site Web ? où se trouve quelque chose ? On parle également d’intention « site web »)
D’autres caractéristiques de la SERP sont affichées lorsque l’intention pour une caractéristique est élevée.
Les recherches qui indiquent le besoin d’un commerce local ou de points de repère à proximité de l’internaute obtiennent une « intention locale » et affichent les packs Google Map.
Une recherche portant sur « chats british short-hair » fait généralement apparaître un pack d’images ou de vidéos bien visible, car l’intention de recherche de photos est élevée.
➽ De nombreuses requêtes ont une intention élevée pour les vidéos et le carrousel de vidéos s’affiche
Comprendre où cela se passe peut aider à développer une stratégie de contenu efficace.

Intention fragmentée
Dans de nombreux cas, une requête peut avoir plusieurs intentions différentes, c’est ce qu’on appelle « l’intention fracturée ».
Google présente une variété d’intentions d’utilisateur pour une requête qui n’est pas clairement définie. C’est le cas le plus fréquent pour les requêtes générales telles que « chien », pour lesquelles vous trouverez :
des guides et des questions sur les soins à apporter aux chiens
- des vidéos de chiens
- une liste de races de chiens
- et des informations générales sur les chiens
Comparez le type de résultats pour la requête similaire « chiots », où l’intention de l’utilisateur semble être davantage liée à l’adoption d’un chiot et à des photos mignonnes.
Progrès du traitement du langage naturel
Pour comprendre l’intention de l’utilisateur, une machine doit d’abord comprendre comment les mots d’une requête sont liés les uns aux autres.
Le traitement du langage naturel (NLP) permet aux ordinateurs de comprendre :
- le sujet
- le prédicat
- l’objet (SPO)
- les relations plus complexes entre les mots
- leurs significations
- les modificateurs
- les entités
Un ensemble similaire de mots dans un contexte ou un ordre différent peut signifier des choses totalement différentes.
Le lancement de l’algorithme Hummingbird a permis à Google de bien mieux comprendre la « recherche conversationnelle » ou recherche sémantique. Elle permet au moteur de recherche de comprendre la signification des mots clés ou des phrases par le biais du contexte et de la logique.
➽ Le Knowledge Graph de Google leur a permis de comprendre comment les choses (ou les entités) sont connectées
- Il s’agit d’une base de données de faits sur les personnes
- les lieux
- les objets
- sur la façon dont ils sont liés les uns aux autres
- sur la signification de ces relations
Google a annoncé le lancement de sa couche thématique au sein de son Knowledge Graph, qui est « conçue pour comprendre en profondeur un espace thématique et la manière dont les intérêts peuvent se développer au fil du temps, à mesure que la familiarité et l’expertise augmentent. »
- Google peut comprendre ce que veut un utilisateur lorsqu’il tape une requête du type « Quel est ce film sur un tigre dans un bateau ? ».
- Google peut comprendre la structure de la phrase et appliquer son graphe de connaissances aux films et aux entités (choses) qu’ils contiennent.
➽ La création d’un contenu conçu pour répondre à l’intention de l’utilisateur consiste à placer l’utilisateur au premier plan.
Créez du contenu pour répondre aux besoins de l’internaute, pas aux vôtres.
Les gens réagissent positivement lorsque vous les aidez à atteindre leurs objectifs !
Expérience utilisateur (UX)
Qu’est-ce que l’expérience utilisateur par rapport à un système, un site web ou une application ?
L’expérience utilisateur est l’ensemble des sentiments et des perceptions qu’un utilisateur éprouve lorsqu’il utilise un système ou un produit.
Elle comprend chaque étape qu’un utilisateur doit franchir pour interagir avec un système ou le manipuler afin d’atteindre un objectif avec succès.
L’expérience utilisateur est une perception, et les perceptions sont subjectives. Chaque personne a un ensemble unique d’expériences personnelles qui façonnent sa façon d’interagir avec le monde, mais pour créer une expérience utilisateur de qualité, il faut identifier les besoins et les pratiques partagés par des groupes d’utilisateurs spécifiques.
L’objectif est de concevoir une expérience qui soit reconnaissable et qui réponde aux attentes.
- L’expérience idéale avec un système ou un produit est claire
- facile à utiliser
- efficace
- confortable
- elle apporte de la valeur
9 Conseils généraux sur l’expérience utilisateur
- Ne réinventez pas la roue, utilisez des éléments communs et reconnaissables.
- Veillez à ce que les éléments importants soient bien visibles.
- Mettez en évidence les éléments auxquels il faut prêter attention.
- Créez des hiérarchies organisationnelles allant du simple au complexe ou du large au spécifique.
- Comprenez les différents objectifs, chemins et tâches que les utilisateurs peuvent vouloir accomplir.
- Ne mettez pas d’obstacles à l’accomplissement d’une tâche, comme bloquer ou distraire le lecteur du contenu principal de la page.
- Visualisez les étapes nécessaires à l’exécution d’une tâche.
- Trouvez des moyens de réduire les étapes et de rendre la tâche plus rapide.
- Réduisez les frictions, les objections ou les problèmes qui pourraient ralentir ou démotiver un utilisateur dans l’accomplissement d’une tâche.
Ce que l’expérience utilisateur n’est pas
L’expérience utilisateur ne consiste PAS à faire faire à l’utilisateur ce que vous voulez qu’il fasse. Si le seul objectif est de pousser les gens à s’inscrire ou à acheter, l’expérience utilisateur ne sera pas forcément positive.
Comprenez ce que l’utilisateur veut et donnez-lui ce qu’il veut.
- Réalisez vos objectifs marketing en supprimant les obstacles,
- en élargissant les options,
- en offrant des incitations
- et en fournissant des connaissances et un contexte
Comment évaluer l’ « expérience de recherche » ?
Il va presque sans dire que les moteurs de recherche se soucient de l’expérience de l’utilisateur.
Prenez le temps de voir par vous-même à quoi ressemble l’expérience de recherche pour votre public :
- Saisir une requête de recherche
- trouver un résultat pertinent
- visiter la page
- scanner et lire la page visitée
- accomplir une tâche sur la page
- découvrir un contenu connexe sur le même site qui s’aligne sur l’intention de l’utilisateur
L’engagement peut-être le signal le plus puissant.
Engagement : acte de s’engager
Le contenu le plus puissant et le plus attrayant est engageant. Il suscite l’intérêt et l’activité.
➽ Quelles sont les qualités d’un contenu de site Web attrayant ?
- Interactif
- Intéressant
- Unique
- Visuellement agréable
- Facile à lire
- Accomplir des tâches
- Résoudre des problèmes
- Agréable
➽ Créez du contenu avec lequel les utilisateurs peuvent interagir, cliquer, sélectionner des options, personnaliser leur vue, découvrir et apprendre davantage
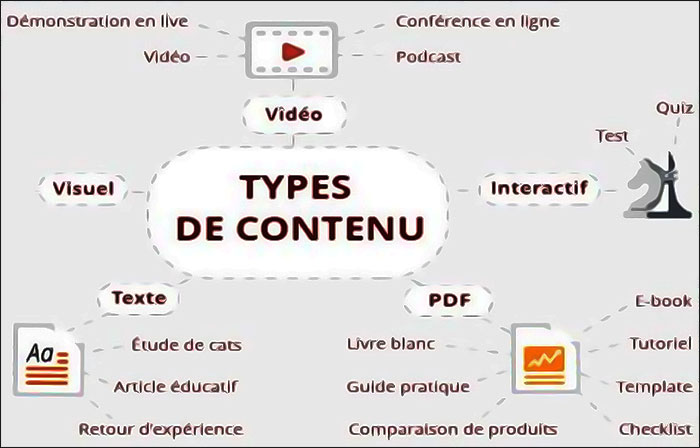
Un article peut être attrayant ou comporter des éléments attrayants, mais essayez d’aller au-delà d’un simple article.
- Pensez à d’autres types de contenu comme les quiz
- les sondages
- les enquêtes
- les outils
- les calculatrices
- les infographies interactives
- les concours
- les défis
- les récompenses
- les discussions (forum, commentaires, blogs en direct, AMA)
Les gens voudront naturellement partager du contenu attrayant et agréable avec leurs amis et collègues.
Un contenu à fort taux d’engagement générera toujours plus de signaux d’amplification (liens et partages).
La vitesse du site web fait partie de l’expérience utilisateur
Le temps de chargement des pages Web est également un facteur de l’expérience utilisateur. Une grande importance a été accordée à l’optimisation de la vitesse des sites Web depuis que Google a annoncé qu’il s’agissait d’un facteur de classement léger en 2010.
Une mise à jour en 2018 a fait entrer en ligne de compte la vitesse des pages Web mobiles, alors qu’auparavant, seule la version de bureau du site était prise en considération.

Google continue de souligner que la mise à jour » n’affectera que les pages qui offrent l’expérience la plus lente aux utilisateurs et n’affectera qu’un petit pourcentage de requêtes … L’intention de la requête de recherche est toujours un signal très fort, de sorte qu’une page lente peut encore être bien classée si elle a un excellent contenu pertinent. »
Quoi qu’il en soit, l’optimisation de la vitesse sur un site Web peut contribuer à l’engagement des utilisateurs, et l’importance de ce facteur de classement augmentera avec le temps.
Si vous vous demandez pourquoi vos pages ne sont pas bien classées, ne commencez pas par accuser la vitesse des pages. Il est beaucoup plus probable que vous deviez créer un contenu de meilleure qualité qui réponde aux attentes des utilisateurs.
- L’outil PageSpeed Insights de Google teste la vitesse de vos pages et identifie les endroits où vous pouvez améliorer la vitesse.
- WebPageTest est un autre excellent outil pour tester les performances d’un site Web.
Les pages d’erreur nuisent à l’expérience des utilisateurs
Les liens brisés créent de mauvaises expériences pour les utilisateurs.
Vérifiez votre page après sa publication et ne créez pas accidentellement de mauvais liens.
Internet est un système en constante évolution et, sur plusieurs années, des pages peuvent être retirées ou cassées.
La Search Console de Google signale ces erreurs comme des erreurs de couverture d’index, ou vous pouvez parcourir votre propre site pour découvrir tous les liens brisés, internes ou externes.
- Ne laissez pas votre site se dégrader
- vérifiez les liens
- réparez-les s’ils ne fonctionnent plus
- entretenez vos pages à long terme
- configurez la redirection si vous modifiez vos propres URL
Cela contribuera à réduire les erreurs et à maintenir la valeur des liens externes que le site a accumulés.
Facteurs d’utilisation des appareils mobiles
Google a compris que les internautes utilisent différents appareils pour effectuer leurs recherches sur internet.
Les sites Web doivent être construits pour bien fonctionner sur les grands écrans comme sur les petits. En 2015, les recherches sur téléphone mobile ont dépassé les recherches sur ordinateur de bureau, s’établissant autour d’une répartition 60 /40 (mobile/ordinateur de bureau).
La même année, Google a lancé la « mise à jour mobile-friendly » qui a classé les sites Web offrant une bonne expérience mobile plus haut dans la recherche mobile.
Plus récemment, en 2018, Google est passé à l’ » indexation mobile-first » , où il crawle et indexe les sites Web en utilisant un agent pour smartphone afin de mieux comprendre l’expérience d’une page sur un téléphone mobile.
Bien que le volume de recherche global soit plus élevé pour les appareils mobiles par rapport aux ordinateurs de bureau, pour de nombreux sites Web B2B, l’ordinateur de bureau/portable représente toujours une plus grande partie de leur trafic car les gens ont tendance à utiliser des ordinateurs portables et de bureau avec des écrans plus grands sur leur lieu de travail.
Cela vaut la peine de vérifier quels sont les appareils qui accèdent le plus souvent à votre site Web.
Si vous utilisez Google Analytics, vous trouverez ce rapport dans Audience > Mobile > Overview.
➽ Google recommande un site Web réactif qui s’étire et s’adapte aux écrans de différentes tailles tout en conservant le même code de page pour tous
Un site réactif utilise des feuilles de style en cascade (CSS) pour remodeler le modèle de page en fonction des différentes fenêtres d’affichage ou largeurs d’écran.
La chose la plus importante à comprendre dans l’indexation mobile-first est le maintien de la parité entre les versions mobile et desktop.
Google peut passer à côté d’informations importantes si votre page mobile offre une expérience différente ou présente moins de contenu ou de liens que la version de bureau. Veillez à suivre toutes les bonnes pratiques de Google pour l’indexation mobile-first.
Contenu frais
Le plus souvent, les internautes recherchent du contenu récemment publié sur un sujet donné
- Les contenus plus anciens finissent par se périmer
- les références deviennent obsolètes
- les idées sont mises à jour
- et le progrès avance
Cela ne veut pas dire que le vieux contenu est négatif, mais un site Web qui ne publie pas de nouveau contenu à un rythme régulier sera considéré comme faisant moins autorité qu’un site Web qui publie du nouveau contenu de qualité à un rythme rapide.
Dernières nouvelles
Comme au bon vieux temps, l’éditeur qui obtient le scoop de l’actualité gagnera en autorité auprès de son public. Google a conçu ses algorithmes spécifiquement pour remarquer et valoriser le contenu frais.
Les sites Web qui parviennent à maintenir une production de contenu élevée tout en préservant la qualité s’imposeront naturellement comme une autorité dans leur domaine. Soyez le premier à publier les nouveautés, capitalisez sur les tendances du moment car demain, il y aura du nouveau.
Même si votre activité ne concerne pas la publication d’actualités, vous pouvez tirer parti des sujets tendances en :
- alignant votre contenu sur les dernières nouvelles
- les tendances saisonnières/de vacances
- ou les grands événements
Pour les deux derniers : saisonniers et événements, planifiez votre contenu à l’avance et soyez prêt à publier au bon moment.
La communauté, c’est génial !
Certains sites Web créent du contenu frais en encourageant le contenu généré par les utilisateurs (UGC).
- Il peut s’agir de critiques
- d’évaluations
- de vidéos
- ou de questions et réponses des utilisateurs
Les sites de réseaux sociaux et les forums créent beaucoup de contenu généré par les utilisateurs.
Les sites Web qui valorisent leur communauté et encouragent l’interaction bénéficient d’une augmentation naturelle de leur référencement.
Google apprécie l’engagement parce que les gens l’apprécient.
Il n’est pas facile de maintenir une communauté active, mais voici quelques conseils :
- Veillez à surveiller et à nettoyer les spams.
- Résolvez les litiges et faites en sorte que les interactions restent positives.
- Les utilisateurs sont généralement plus intéressés à rejoindre une discussion en ligne qui a déjà lieu, vous devez donc lancer la conversation.
- Trouvez des moyens de « lancer » des discussions intéressantes.
- Identifiez les « utilisateurs puissants » de votre communauté qui publient souvent, veulent aider et lancent des conversations. Entretenez une relation avec les utilisateurs actifs et donnez-leur les moyens de contribuer au maintien d’une communauté conviviale.
Algorithme de fraîcheur
Google a annoncé en 2011 qu’il disposait d’algorithmes permettant d’identifier la « fraîcheur des requêtes » (QDF).
Cela signifie qu’il peut utiliser des modèles mathématiques pour identifier les requêtes où le contenu publié plus récemment devrait être favorisé par rapport au contenu plus ancien.
Taux de clics (CTR)
Qu’est-ce que le CTR ?
Le taux de clics est le pourcentage d’utilisateurs qui cliquent sur votre résultat de recherche après qu’il leur a été présenté.
Le nombre d’impressions est le nombre de fois qu’un résultat a été affiché. La formule du CTR est la suivante :
Clics ÷ Impressions = CTR
Avertissement : Les représentants de Google ont déclaré à plusieurs reprises que le CTR n’est pas un signal de classement. Ils ont dit qu’il ne s’agissait pas d’un facteur de classement direct, mais qu’il pouvait s’agir d’un facteur de classement indirect. A-t-il vraiment de l’importance ?
Il est logique que Google ne puisse pas utiliser le CTR comme facteur de classement direct, car il serait trop facile de manipuler ce signal : Il suffit d’engager des millions de personnes pour qu’elles cliquent sur vos résultats de recherche ! Alerte spoiler, cela ne fonctionne pas.
Même si le taux de clics n’est en aucun cas pris en compte par Google, votre site Web dépend toujours des clics des internautes.
Les clics sont du trafic. Google utilise ces données pour informer ses résultats de recherche d’une manière ou d’une autre, et si vous pouvez trouver des moyens d’améliorer votre CTR, vous devriez le faire pour améliorer l’expérience de votre site.
Améliorer le CTR
Si vous voulez améliorer votre taux de clics, vous devez améliorer la façon dont votre page est présentée dans les résultats de recherche. Il existe plusieurs façons d’y parvenir :
- Amélioration du titre et de la méta-description
- Choisir des URL courtes et lisibles
- Fraîcheur, date de publication
- Données structurées, pour obtenir un résultat riche
- Apparition dans d’autres fonctions de recherche, snippets, knowledge boxes, packs ou carrousels
- Utiliser des images pertinentes et attrayantes
La position ou le rang dans le résultat de la recherche est le facteur le plus important pour déterminer le CTR.
Le CTR moyen peut être déterminé en examinant de grands ensembles de données. La distribution du CTR dans une SERP est généralement la même d’une requête à l’autre, mais il existe quelques différences entre les mobiles et les ordinateurs de bureau et entre différents types de requêtes.
A lire ➽ Comment trouver les mots-clés les plus recherchés
Expertise, autorité, fiabilité (E-A-T en anglais)
E-A-T est un concept développé par Google dans ses Quality Rater’s Guidelines (QRG).
Ce document est utilisé pour aider les équipes d’évaluateurs de qualité de Google gérées par des sociétés tierces. Les évaluateurs de qualité sont formés pour juger et noter la qualité des pages Web en fonction du classement des recherches.
Les évaluations de qualité ne sont pas utilisées pour créer les algorithmes de Google, mais plutôt pour tester les modifications récentes des algorithmes. En substance, elles décrivent comment être une page Web de haute qualité.
Ce sont des directives à lire absolument
Elles nous aident à comprendre le système de classement que Google veut créer.
L’E-A-T se recoupe avec beaucoup d’autres facteurs énumérés ci-dessus, c’est un concept important à comprendre pour le SEO, même s’il ne s’agit pas d’un facteur de classement direct.
Google n’a pas de score E-A-T, mais si vous vous efforcez de vous améliorer dans ces domaines, vous obtiendrez un contenu de meilleure qualité qui sera mieux noté par les milliers de « bébés algorithmes » qui travaillent ensemble.
De nombreuses mises à jour majeures de l’algorithme de Google tentent de mieux valoriser le contenu de qualité. En 2011, lors du lancement de la mise à jour Panda, la qualité du contenu a fait l’objet d’une attention particulière.
Étudiez ces questions et portez un regard critique sur votre site Web, vous devrez peut-être demander à quelqu’un d’autre d’y répondre pour vous.
555
Expertise
Google sait que les gens recherchent du contenu de niveau expert. L’expertise peut être en partie jugée par la façon dont les sites Web référencent votre contenu (liens).
Les algorithmes peuvent évaluer l’expertise d’un auteur sur certains sujets, en fonction du nombre d’articles qu’il écrit sur le sujet et de la popularité de ces articles.
Un auteur prolifique et expert peut trouver qu’il est plus facile d’obtenir un classement dans les moteurs de recherche s’il écrit davantage.
- Veillez à fournir au moteur de recherche des informations solides sur les auteurs
- leurs qualifications
- leur expérience
- leurs réseaux sociaux
- et leurs coordonnées
En fonction des informations disponibles, il est possible de relier un auteur à tout le contenu qu’il a écrit sur différents sites Web.
Google estime que certains sujets nécessitent un niveau d’expertise très élevé pour être bien classés. Ils appellent ces sujets « Your Money or Your Life » (YMYL).
- Les sites qui fournissent des conseils juridiques
- sanitaires
- ou financiers sont soumis à des normes d’expertise plus strictes
Des mises à jour plus récentes de l’algorithme ont été effectuées pour renforcer ce signal, en particulier pour les sites Web publiant des informations sur la santé.
Autorité
L’autorité est surtout une question de liens. Plus d’autres sites Web renvoient à un site, plus ce site apparaît populaire aux yeux de Google.
C’est un peu comme un concours de popularité pour les gens, l’autorité a tendance à augmenter plus une personne est mentionnée.
Fiabilité
La mesure de la confiance sur internet peut s’avérer délicate, mais il existe quelques moyens pour un moteur de recherche d’exploiter les données relatives à la fiabilité.
La proximité d’un ensemble de sites Web fiables peut être utilisée pour mesurer la fiabilité. Le concept est le suivant :
- les sites dignes de confiance renvoient généralement à d’autres sites dignes de confiance
- et les sites non dignes de confiance n’obtiennent pas de liens de sites dignes de confiance
Un ensemble de sites Web fiables peut être sélectionné à la main ou par un algorithme, mais quelles sont les caractéristiques communes aux sites que nous savons dignes de confiance ?
L’autre signal qu’un moteur de recherche peut mesurer est le sentiment
Un site non fiable peut avoir beaucoup de liens pointant vers lui, mais le contexte autour de ces liens peut être très négatif.
Le vieil adage est toujours vrai, toute publicité est une bonne publicité, mais Google a tenté de dévaloriser les sites Web qui font la promotion d’expériences négatives ou frauduleuses.
Qu’est-ce que le contenu de qualité ?
Lorsque l’on parle du type de page qui se classe bien dans les moteurs de recherche, les mots « contenu de qualité » sont souvent utilisés, mais qu’entend-on exactement par contenu de qualité ?
Si vous prenez les 9 facteurs ci-dessus, ceux-ci couvrent la plupart de ce qui est considéré comme un contenu de qualité.
- Qualité technique – accessible, pas d’erreurs, pas de fautes
- Unique – contenu utile et informatif, pas de contenu dupliqué
- Liens – comme des votes d’approbation, des indicateurs de qualité
- Couverture thématique – compréhension complète des sous-thèmes.
- Soyez la ressource qui résout le mieux le problème.
- Rendez l’expérience agréable – engageante, bonne conception, pas d’expériences indésirables
- Nouveau contenu, contenu actualisé, actualité, fraîcheur, production élevée au fil du temps.
- Donner envie aux gens de cliquer et de continuer à cliquer pour en savoir plus.
- Niveau expert – créé par un auteur ayant de l’expérience sur le sujet, citations, références.
Directives relatives aux moteurs de recherche
Google détient 92 % du marché international des moteurs de recherche, il est donc de la plus haute importance de suivre leurs directives. Celles-ci résument en quelque sorte tout : n’enfreignez pas les règles, sinon vous êtes éliminé !
Nous avons déjà abordé la plupart de ces directives générales ci-dessus, mais il est intéressant de voir comment Google en parle. Il s’agit d’une version résumée des directives pour les webmasters de Google :
Veillez à poursuivre la lecture de l’ensemble des consignes générales, des consignes spécifiques au contenu et, surtout, des consignes de qualité, qui vous indiquent ce qu’il ne faut pas faire.
Vous serez pénalisé par Google si vous ne respectez pas ces consignes.
Sur le site officiel de Google ➽ Bien débuter en référencement naturel (SEO)
Pourquoi le SEO est-il important ?
L’amélioration de la présence internet est essentielle pour accroître la notoriété d’une marque
Les efforts déployés pour créer un site Web de qualité profiteront à votre entreprise sur le long terme. Les résultats du SEO sont durables et à long terme.
Au fur et à mesure de vos efforts et du développement de votre autorité, vous constaterez qu’il devient plus facile d’obtenir de nouveaux classements au fil du temps, car votre domaine et votre site Web puissants distribuent de l’autorité à toutes vos pages.
« Ne perdez jamais de vue le fait que tous les signaux de classement SEO tournent autour d’un contenu quelconque. » – Duane Forrester
Votre site Web est votre château
Votre contenu est la douve qui entoure votre château.
Plus ces douves sont larges (complètes) et profondes (de qualité supérieure), plus il sera difficile pour un concurrent de vous envahir.
Au fur et à mesure que votre visibilité dans les moteurs de recherche augmente, vous gagnez en crédibilité auprès des utilisateurs qui considèrent votre marque comme un leader d’opinion dans ce domaine.
Au final, cela renforce la confiance, qui est peut-être le facteur le plus important pour encourager les gens à devenir de nouveaux clients.
➽ Une suite logicielle SEO complète
SEMrush est un ensemble très impressionnant d’outils de référencement et de marketing numérique.
➽ Avantages de SEMrush
Vous avez un blog ou un site web ? Je propose mes services de rédaction web : création et mise à jour d'articles optimisés SEO, maintenance de blog, audits de contenu, refonte éditoriale.
Si vous cherchez quelqu'un pour s'occuper de votre contenu — articles, mises à jour, stratégie éditoriale — contactez-moi, on en discute.
SEMrush a un outil pour chaque aspect du référencement. Quel que soit l’aspect sur lequel vous devez travailler, des listes de référencement local aux campagnes de contenu créatif, SEMrush vous aidera à obtenir de meilleurs résultats.

Visitor Rating: 5 Stars