
Bonjour à tous, ici sur Des Geeks et des lettres. Dans l’article d’aujourd’hui, nous allons voir quelques-uns des termes couramment utilisés dans le domaine de l’IA. Si vous êtes un ingénieur qui développe des applications, ces termes vous seront utiles pour communiquer avec les membres de votre équipe ou avec des personnes extérieures. Je pense également que la connaissance de ces termes vous permettra d’approfondir plus facilement vos connaissances sur l’IA.
À la fin de cet article, vous disposerez d’une liste de termes dont vous comprendrez parfaitement la définition. Je mettrai également quelques références dans la description afin que vous puissiez approfondir vos connaissances. Commençons.
Le premier terme que vous devez connaître est celui de « grand modèle linguistique » (large language model)
Également appelé LLM, il s’agit d’un réseau neuronal entraîné à prédire le terme suivant d’une séquence d’entrée.
Par exemple, si je soumets la requête « tout ce qui brille » à un grand modèle linguistique, celui-ci va générer la réponse « n’est pas de l’or ». À ce stade, la réponse complète « tout ce qui brille n’est pas de l’or » est renvoyée à l’utilisateur.
Qu’entend-on par « entraînement » ? Qu’entend-on par « réseau neuronal » ? Au fur et à mesure que nous avancerons dans cet article, vous comprendrez mieux ces termes, un par un.
Le deuxième terme que nous examinons est la tokenisation
Cela concerne le traitement de l’entrée d’un grand modèle linguistique. Par exemple, si tout ce qui brille est transmis à un grand modèle linguistique, la première chose qu’il fera sera de le diviser en tokens discrets. C’est le processus de tokenisation.
Le premier token sera « all ». Ensuite, il y aura un espace. Puis viendra « glit » et enfin « ers ». Vous vous demandez peut-être pourquoi il ne suffit pas de diviser cette phrase en espaces pour obtenir le résultat souhaité. Les humains ne parlent pas ainsi. Après tout, nous essayons de traiter le langage naturel.
Est un terme courant. Shimmers, murmurss, flickers. Ce sont des termes qui ont le suffixe qui signifie que l’action de glit est effectuée par cet objet. Un autre exemple est ing en anglais. Ainsi, eating, dancing, singing ont tous le suffixe ing. Et un grand modèle linguistique peut examiner ce token ing et savoir que l’action précédente est effectuée tant que vous avez ce suffixe.
N’oubliez pas que le problème central pour un grand modèle linguistique est de vraiment comprendre le langage humain afin de pouvoir le parler correctement. La tokenisation est une partie essentielle de ce processus, dont le résultat final est que le texte saisi est divisé en tokens.
Ce qui nous amène à notre troisième vecteur de termes
Les tokens vous indiquent sur quoi vous devez vous concentrer. Quel est le plus petit terme à partir duquel vous pouvez dériver un sens ? Mais le sens à dériver est représenté par des vecteurs.
Si le grand modèle linguistique peut cartographier un espace bidimensionnel ou n-dimensionnel de manière à ce que tous les mots proches en termes de sens soient placés à proximité les uns des autres, l’avantage sera que la signification de ces mots sera transformée en une coordonnée dans cet espace n-dimensionnel. C’est ce qu’on appelle un vecteur.
La coordonnée qui cartographie un mot dans un espace à n dimensions de telle sorte que les mots proches, les mots de sens similaire, sont tous regroupés et que les mots de sens opposé sont éloignés, est obtenue grâce au processus de vectorisation.
Le résultat final est que les grands modèles linguistiques connaissent la signification inhérente de tous les mots du vocabulaire anglais et savent également comment les décomposer en petits tokens.
Tout texte saisi est converti en tokens. Les mots similaires sont placés à proximité les uns des autres. Une fois qu’ils connaissent la signification, ils peuvent construire des phrases efficacement.
Vous disposez donc désormais de grands modèles linguistiques capables de tokeniser le texte saisi et de le convertir en vecteurs.
Mais il existe un défi majeur qui a bouleversé l’ensemble du secteur et rendu les grands modèles linguistiques très populaires : l’attention.
Nous venons de dire que tous les tokens d’entrée d’un grand modèle linguistique sont convertis en vecteurs. Les vecteurs encapsulent la signification de ces mots. Mais qu’en est-il du mot « pomme » ?
Lorsque vous dites « c’est une pomme savoureuse », vous faites référence au fruit, à la pomme comestible. Lorsque vous dites « les revenus d’Apple », vous faites probablement référence à l’entreprise. Et si vous dites « la prunelle de mes yeux », vous parlez probablement d’une jeune personne pour laquelle vous avez de l’affection.
Le mot « apple » a donc différentes significations et la seule façon de comprendre le sens n’est pas de regarder le mot lui-même, car son orthographe est exactement la même, mais de regarder les mots qui l’entourent et qui ajoutent du contexte à la signification du mot « apple ».
Dès que j’ai dit « savoureux », vous savez qu’il va parler d’un aliment. C’est ainsi que les humains déduisent le sens, et les grands modèles linguistiques peuvent également le faire de cette manière.
Pour ce faire, ils examinent les mots proches dans une phrase et génèrent ces vecteurs. Les vecteurs contextuels proches sont donc sélectionnés et, pour les termes ambigus, vous obtenez des vecteurs ambigus.
Mais vous pouvez en déduire le sens exact en y ajoutant ce vecteur contextuel proche. Prenez donc le vecteur de la pomme, prenez le vecteur du revenu. Lorsque vous ajoutez ces deux vecteurs, lorsque vous effectuez une sorte d’opération, il ne s’agit pas d’une addition directe, mais d’une opération d’attention.
Vous prenez effectivement le vecteur de la pomme et vous le poussez dans la direction de la société Apple. Google, Meta et Microsoft sont donc tous ici. La première opération du vecteur « revenu » va l’envoyer là-bas. Si vous ajoutez à la place un vecteur « savoureux » à cela, si vous effectuez le mécanisme d’attention de ces deux vecteurs, alors cela va pousser le vecteur « pomme » vers « banane », « chiku » et « goyave ».
D’accord ? Vous pouvez donc tokeniser le texte saisi. Vous pouvez dériver la signification inhérente de tous ces tokens. Et pour les tokens ambigus, difficiles à comprendre, vous disposez d’un mécanisme permettant d’ajouter du contexte en examinant les mots voisins. Il s’agit là d’une autre avancée majeure réalisée par les grands modèles linguistiques.
C’était en 2017. L’article a été publié à cette époque, mais c’est en 2022, avec la sortie de ChatGPT, que cette technologie est devenue vraiment très célèbre. La qualité des réponses d’un grand modèle linguistique dépasse de loin tout ce que nous avons vu auparavant.
En effet, il est capable de déduire le sens contextuel. Il est capable de construire des phrases à la manière dont les humains s’expriment.
Nous savons maintenant comment les LMS peuvent traiter les entrées
Mais comment entraîner le LM à prédire le prochain token ? C’est là qu’une avancée majeure a eu lieu en 2017. En gros, le concept d’apprentissage auto-supervisé est devenu très populaire.
L’apprentissage auto-supervisé signifie qu’au lieu de dire au modèle exactement ce qu’il doit faire, la structure des données d’entrée est telle que le modèle sait ce qu’il doit faire.
Par exemple, vous lisez cet article en ce moment. Je vais rendre une partie de cet article vide. Donc 1 2 3 4 5. Que pensez-vous qu’est caché en ce moment ? Quel chiffre vous vient à l’esprit ? Voyons si c’est juste.
Oui, la plupart d’entre vous ont deviné un, car nous avons suivi la séquence 5 4 3 2 1. Ce qui se passe, c’est qu’une partie de l’entrée peut être prédite même si vous laissez cette partie vide, ce qui signifie qu’il existe une structure inhérente à votre entrée que votre esprit est capable de remplacer par le token attendu ou la sortie attendue.
La méthode standard pour entraîner un tel modèle s’appelle l’apprentissage supervisé, dans lequel un être humain dit que si le texte d’entrée est « tout ce qui brille », alors le modèle doit prédire que ce n’est pas de l’or. Si le texte d’entrée est « at two », alors la sortie devrait être « brutus ».
Au lieu de cela, l’apprentissage auto-supervisé a rendu l’obtention de données de test beaucoup moins coûteuse. Ici, si vous avez « at two brutus », alors le modèle va être alimenté par ce texte et il va faire trois prédictions.
Une : qu’est-ce qui vient après ? Deux : qu’est-ce qui vient après « at two » et trois : qu’est-ce qui vient après « Brutus ». Aucun être humain n’a été impliqué. Vous aviez du texte dans le monde. Vous l’avez peut-être récupéré sur Internet et vous dites maintenant au modèle : « Écoute, j’ai trois questions à te poser. Dis-moi quelles sont les bonnes réponses. »
Le modèle examine donc ces trois énigmes. Elles sont toutes traitées en parallèle et il tente de faire des prédictions. Le modèle peut donc dire « non ». Le modèle peut dire « deux ». Le modèle peut dire quelque chose, mais vous entraînez le modèle à répondre « deux ».
S’il fait une erreur, vous pénalisez le modèle, ce qui augmente la perte, et les poids du réseau neuronal sont mis à jour.
Dans la deuxième tâche, si le modèle prédit Brutus, vous lui dites que c’est très bien et que les poids n’ont pas besoin d’être mis à jour, mais s’il dit César, le modèle doit être pénalisé et les poids internes sont mis à jour.
Dans le troisième cas, si vous prédisez un token d’arrêt comme Brutus, c’est tout. Vous vous trompez alors. S’il s’agit d’une virgule, vous avez raison. Et s’il s’agit de « alors », vous avez peut-être aussi raison.
Ce que vous faites, c’est que vous examinez un texte qui existe déjà dans le monde et vous vous créez plusieurs défis sans intervention humaine. C’est ce qui rend le modèle auto-supervisé.
Cela peut sembler insignifiant, mais cette décision architecturale ou cet avantage du grand modèle linguistique le rend vraiment très évolutif.
En fait, la plupart des modèles d’IA passent désormais à l’apprentissage auto-supervisé. Même les modèles d’images dont nous avons parlé cherchent à supprimer certaines parties de l’image et à essayer de prédire ces parties.
L’avantage est que vous comprenez la structure sous-jacente et la signification inhérente de ces parties. Dans le cas du texte, il s’agit de termes. Dans le cas des images, il s’agit d’un ensemble de pixels.

Ce qu’est l’apprentissage auto-supervisé
Passons maintenant au transformateur. Bon, la plupart des gens confondent le transformateur avec le grand modèle linguistique, ce qui est tout à fait compréhensible, mais ce n’est pas le cas.
Un grand modèle linguistique est un modèle qui prédit le prochain token à partir d’une séquence d’entrée. Un transformateur fait exactement la même chose, mais il s’agit d’un algorithme ou d’une méthode spécifique permettant de prédire le prochain token.
Un transformateur consiste essentiellement à faire passer les tokens d’entrée par un bloc d’attention, qui est ensuite transmis à un réseau neuronal, un réseau neuronal à propagation directe. Vous obtenez alors un ensemble de sorties. Vous pouvez les considérer comme des vecteurs de sortie.
Ces vecteurs sont ensuite transmis à une autre couche d’attention. Comme nous l’avons dit, la première couche d’attention permet de lever l’ambiguïté des termes. La deuxième couche peut trouver des relations plus complexes. Elle peut trouver du sarcasme. Elle peut trouver des implications.
Par exemple, une grue chassait un crabe. Dans le premier cas, vous avez compris qu’il ne s’agissait pas d’une grue métallique, mais d’un oiseau. Mais dans le second cas, vous pouvez déduire que le crabe a peur. Vous pouvez comprendre que la grue a faim.
Il s’agit donc du deuxième niveau, puis vous disposez d’un autre réseau neuronal à propagation directe, et ainsi de suite jusqu’à ce que vous soyez suffisamment sûr de vous pour générer un résultat.
Vous disposez de ces niveaux empilés, parfois jusqu’à 12 niveaux, parfois plus. Je pense que les architectures GPT récentes en comptent des centaines.
L’idée principale derrière cela est que vous obtenez toute la signification de vos jetons d’entrée, puis vous les manipulez encore et encore pour finalement prédire quel devrait être le mot suivant.
Ce bloc d’attention est de l’ordre n². D’accord, vous pourriez remplacer ce transformateur dans un grand modèle linguistique par autre chose.
Demain, une nouvelle architecture pourrait voir le jour, dans laquelle le transformateur et les modèles d’espace d’état seraient supprimés, ce qui pourrait être un modèle de diffusion qui construit des essais ou du texte.
Le grand modèle linguistique est en fait le produit. Vous pouvez le considérer comme une voiture et ceci comme le moteur. Beaucoup de gens disent qu’une voiture n’est que son moteur, mais non, il y a d’autres éléments sophistiqués autour. L’algorithme interne peut être différent.
Terme numéro sept : le réglage fin
Nous avons dit qu’un grand modèle linguistique est un modèle entraîné à prédire le terme suivant d’une séquence d’entrée. La question est : de quel type de token suivant parlons-nous ?
Si vous parlez d’un grand modèle linguistique médical, qui aide les médecins à expliquer le diagnostic d’un patient, vous pensez probablement à des termes médicaux.
Si vous disposez d’un modèle entraîné sur les opérations financières, alors le même modèle pour la même requête va raisonner en termes financiers.
Le terme suivant proposé par le modèle ne sera donc pas toujours général. Vous allez d’abord entraîner votre modèle de base de manière auto-supervisée.
Ensuite, vous allez prendre ce modèle et lui faire passer une série de questions et réponses. Ce processus s’appelle le réglage fin et se déroule à peu près comme suit : qui est le président des États-Unis ? Donald Trump.
Mais le modèle pourrait aussi répondre : « J’aimerais bien le savoir moi aussi. C’est là que les choses tournent mal. Le modèle ne devrait pas répondre ainsi. Il devrait nous donner une réponse directe ou avouer qu’il ne sait pas, ou encore dire non, mais cela serait également très mauvais, car les modèles sont entraînés pour être utiles.
Ce qui se passe, c’est que d’autres réponses plausibles, qui ne sont pas fausses mais qui ne sont pas souhaitables, sont pénalisées dans le processus de réglage fin. Vous avez ces questions et réponses. Le processus de réglage fin oblige le modèle à prendre une question et à donner les réponses attendues.
Ainsi, lorsqu’il s’agit d’un diagnostic médical, le modèle va s’entraîner lui-même. Les pondérations internes seront mises à jour de manière à ce qu’il apprenne à parler en jargon médical ou en termes médicaux.
Cette étape, au cours de laquelle un modèle de base est entraîné à répondre d’une manière spécifique, est appelée « ajustement ». Le même modèle de base peut être soumis à différents ensembles de questions et réponses afin d’obtenir plusieurs modèles ajustés.
Le modèle de base de Llama peut donc être ajusté par une entreprise afin de répondre aux questions spécifiques de ses clients.
Prompting Fewshot
L’idée principale derrière le fewshot prompting est donc, avant d’envoyer une requête à un modèle, avant d’envoyer une simple requête manuelle à un grand modèle linguistique et de lui demander de fournir une réponse.
Vous enrichissez la requête. Vous ajoutez plus d’informations en disant : « Si la requête est « où est mon colis », alors laissez-moi vous dire qu’il y a quelques exemples que je voudrais que vous examiniez. »
Cela se produit pendant le temps d’inférence, pendant le temps de réponse en production, en direct, votre système, votre serveur envoie la requête originale et envoie des exemples au modèle afin qu’il les intègre dans le contexte du texte et donne ensuite une réponse appropriée.
La qualité de la réponse s’améliore. C’est ce qu’on appelle le few short prompting. Il s’agit essentiellement d’un exemple de prompting. Un exemple dans le prompt. C’est tout.
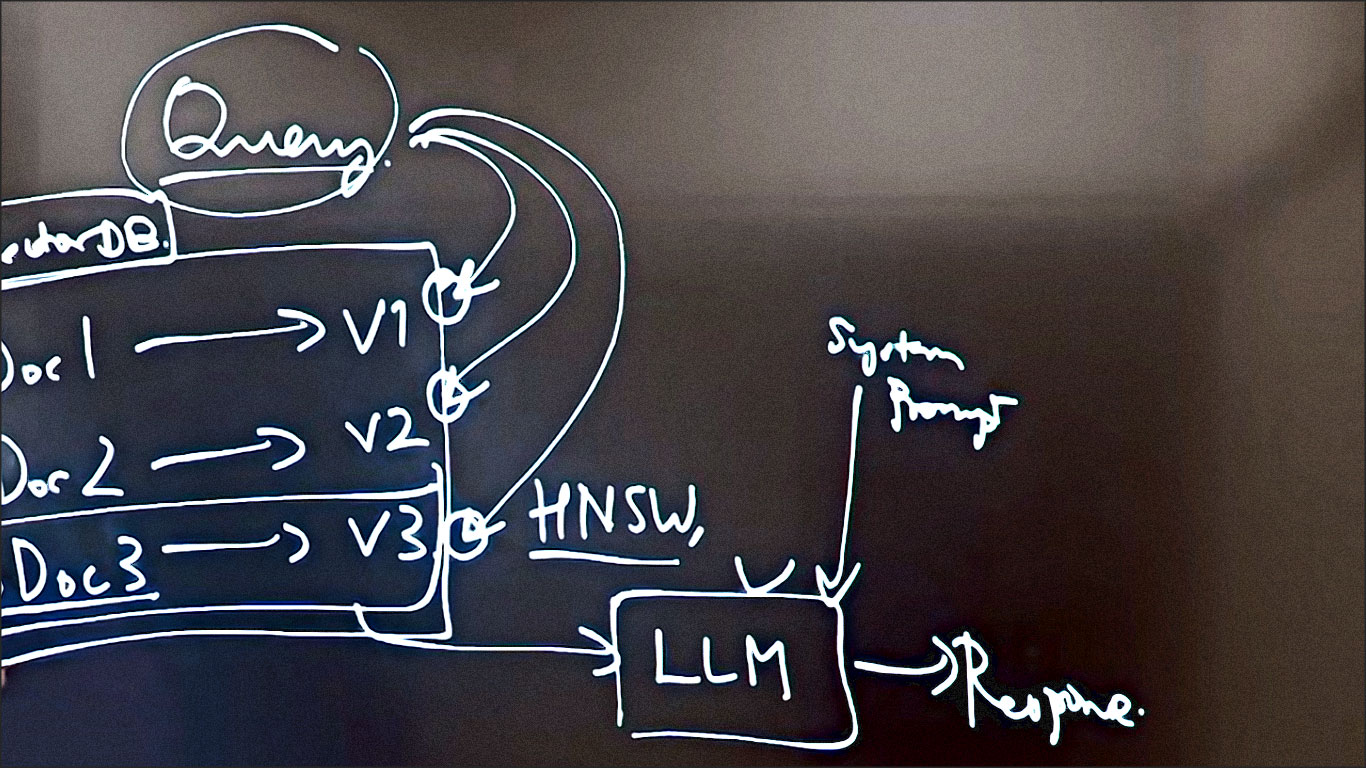
Cela nous amène au point numéro neuf : La génération augmentée par la récupération (retrieval augmented generation)
En fait, le domaine de l’IA évolue si rapidement que certains affirment que la génération augmentée par la récupération (rag) est déjà morte.
L’idée de base est donc, encore une fois, que vous disposez d’un grand modèle linguistique et que vous transmettez les données d’entrée provenant du serveur.
Un client se connecte donc à vous ici. Il accède à votre API. Le serveur dit : « Vous savez ce qu’est la requête du client. Transmettons-la au dernier modèle linguistique. En même temps, donnons quelques exemples. »
Il s’agit donc de quelques invites courtes et, comme il existe certaines politiques d’entreprise que je souhaite vous faire connaître concernant les grands modèles linguistiques, je vais vous fournir ces documents.
En temps réel, le serveur va donc chercher les documents les plus pertinents, peut-être votre document de politique, peut-être vos conditions générales de vente, et peut-être bien d’autres choses encore. Vous envoyez ces documents avec des exemples de réponses à donner.
Cela vous donne une bonne idée du format de la réponse. Cela vous donne une bonne idée du contexte spécifique à l’entreprise et il s’agit là de la requête directe de l’utilisateur.
Grâce à tout cela, le grand modèle linguistique a tendance à fournir des réponses de très haute qualité.
La question est maintenant de savoir d’où proviennent ces documents. Comment le serveur sait-il quels documents sont liés à quelle requête ? Il existe de nombreuses façons de procéder.
Si vous vous adressez à Neo4j, une société spécialisée dans les bases de données orientées graphe, elle vous dira que vous devez stocker les données dans une base de données orientée graphe.
Si vous vous adressez à Neon, ils vous diront que vous devriez stocker les données dans une base de données vectorielle. Et certaines personnes vous diront simplement de tout conserver en mémoire. Conservez tout dans le cache. La manière dont vous récupérez les documents n’a pas beaucoup d’importance. En général, il s’agit d’une base de données vectorielle, car il est plus facile de trouver les documents pertinents en effectuant simplement une recherche par similarité.
Une fois que vous avez les documents, vous les transmettez à un grand modèle linguistique. Le grand modèle linguistique les convertit en interne en vecteurs, puis vous donne une réponse. Mais à un niveau élevé, vous voulez simplement ajouter de plus en plus de contexte. Vous récupérez le contexte, enrichissez la requête, puis générez une réponse.
Le 10e terme est la base de données vectorielle
Nous venons de mentionner que la base de données vectorielle est utilisée pour trouver des documents pertinents pour une requête entrante. Voyons comment cela se passe.
Vous avez la requête « Je suis mécontent de votre système de paiement. J’attends un remboursement. » Cette requête contient beaucoup de termes.
Un être humain peut lire cela et comprendre facilement ce que ressent l’utilisateur. Il est mécontent. Il l’a clairement mentionné, mais il souhaite obtenir un remboursement. Si vous lui accordez un remboursement, son mécontentement disparaîtra peut-être.
Que faites-vous ? Quels documents recherchez-vous ? Vous pourriez rechercher tous les documents dans lesquels le mot « mécontent » apparaît.
Mais peut-être que cela ne figure pas dans la politique de votre entreprise. Peut-être qu’il n’est mentionné nulle part qu’un utilisateur est contrarié. Mais vous disposez d’un document qui mentionne si l’utilisateur vous attribue une note faible ou s’il abandonne.
Comment décidez-vous que le mot « contrarié » est proche d’une note faible ou d’un abandon ? Nous avons parlé des vecteurs. Les vecteurs peuvent encapsuler la signification sémantique, ce qui signifie que les documents qui stockent des mots similaires seront similaires ou proches en distance.
N’oubliez pas que les vecteurs sont essentiellement des coordonnées, n’est-ce pas ? La distance entre « upset » et les documents ayant une note faible sera donc faible. Vous récupérerez les documents qui mentionnent une note faible ou des abandons et les utiliserez pour ajouter du contexte à votre grand modèle linguistique.
Lorsque vous recevez une requête de l’utilisateur, vous allez trouver le document le plus proche de la requête et l’ajouter au contexte des grands modèles linguistiques. Ce document sera donc envoyé avec la requête originale de l’utilisateur et éventuellement une invite du système. Où allez-vous stocker ces documents ? Dans une base de données vectorielle qui vous aide à effectuer efficacement ces recherches de similarité.
Certains de ces algorithmes sont hiérarchiques et navigables dans un petit monde. Nous en avons parlé en détail dans le cours « Interview Ready ». En fin de compte, la base de données vectorielle est comme une boîte noire pour vous. Vous pouvez y stocker des documents et les récupérer rapidement lorsque vous en avez besoin.
Parfait. Vous pouvez donc stocker les documents et informations internes de l’entreprise dans une base de données vectorielle afin d’obtenir le contexte pour un modèle linguistique volumineux. Mais que se passe-t-il si le contexte existe en dehors de votre système ?
Ce défi a été relevé grâce au protocole de contexte du modèle
Comme son nom l’indique, il s’agit d’un protocole ou d’un moyen de communication permettant de transférer le contexte dans un modèle.
L’idée de base ici est que vous disposez d’un grand modèle linguistique qui, avant de recevoir une requête entrante d’un utilisateur, dispose d’un client, un client MCP, un client de protocole de contexte de modèle qui transmet la requête initiale de l’utilisateur. Le LM prend alors une décision. Il indique qu’il peut exister des outils ou des bases de données externes auxquels je souhaite me connecter. Le client en est informé et se connecte à des serveurs MCP externes.
Dans un cas, il peut s’agir d’Indigo. Dans un autre cas, il s’agira d’Air France, dont le serveur MCP peut vous fournir des informations détaillées sur Air France. Vous pouvez donc considérer cela comme une enveloppe pour la base de données d’Air France. Il s’agit d’une enveloppe pour la base de données d’Indigo.
En réponse, vous obtiendrez les détails des vols de chacune de ces compagnies aériennes. Une fois que vous disposez de ces détails, vous pouvez les transmettre au LM en indiquant que, outre la requête de l’utilisateur et les invites système ou le contexte pertinent que j’ai pu obtenir à partir de ma base de données vectorielle, j’ajoute également les détails des vols, des informations en temps réel provenant de serveurs externes que vous pouvez désormais utiliser pour prendre une décision.
À ce stade, le grand modèle linguistique pourrait dire « OK, réservez le vol numéro Indigo 1020 », ce qui entraînerait un autre appel API pour effectuer la réservation sur le serveur MCP d’Indigo. La réponse finale est transmise au client MCP. Le client la retransmet ensuite à l’utilisateur. Il en résulte la satisfaction du client.
Vous voyez que l’utilisateur n’est plus seulement en mesure d’obtenir des données. Il n’a plus besoin de faire quoi que ce soit lui-même après avoir reçu une recette. La recette peut être entièrement exécutée par le client MCP.
D’accord, cela rend donc le LMS beaucoup plus puissant. Le MCP a désormais gagné en popularité.
Tout cela mis ensemble s’appelle l’ingénierie contextuelle
Si vous êtes ingénieur en IA, vous avez probablement déjà entendu ce terme. Il s’agit essentiellement d’une synthèse de nombreux éléments que nous avons déjà abordés.
Nous avons discuté de quelques invites courtes qui donnent des exemples. Nous avons discuté de la génération augmentée par récupération, qui consiste à obtenir des documents pertinents à partir d’une base de données vectorielle et à les utiliser pour ajouter du contexte à une requête, puis à utiliser le protocole de contexte du modèle pour accéder à des serveurs externes et effectuer les actions nécessaires.
En matière d’ingénierie contextuelle, nous sommes confrontés à deux nouveaux défis en tant qu’ingénieurs en IA. Le premier concerne les préférences des utilisateurs et le second la synthèse des invites. On peut appeler cela la synthèse contextuelle. Par exemple, vous pouvez utiliser une fenêtre glissante où les 100 dernières conversations sont envoyées directement au grand modèle linguistique et toutes les conversations précédentes sont résumées en cinq phrases.
Cela limite le nombre maximal de chats que vous envoyez au grand modèle linguistique. Vous pouvez également utiliser d’autres techniques. Par exemple, certaines personnes se concentrent uniquement sur les mots-clés. D’autres se concentrent uniquement sur le dernier chat.
Donc, un chat et le résumé de l’historique complet des chats précédents. L’idée est d’obtenir un résumé du contexte de cette manière. Lorsque vous recevez un document, vous le résumez d’abord, puis vous l’envoyez. Cela peut être fait en utilisant un petit modèle linguistique peu coûteux ou un modèle distillé. Une fois que vous avez généré le contexte, vous l’envoyez au grand modèle linguistique coûteux.
La principale différence entre l’ingénierie contextuelle et l’ingénierie des invites est que cette dernière concerne une seule invite. Elle est sans état.
Chaque fois que vous demandez au dernier modèle linguistique de se comporter d’une manière particulière, l’invite du système sera la même. Mais l’ingénierie contextuelle évolue en fonction des préférences déclarées par l’utilisateur et de l’historique des conversations précédentes.
Similaire à ce qui existait auparavant, mais à plus long terme, ce qui nous amène à la chose la plus durable que vous puissiez imaginer actuellement dans le domaine de l’IA : les agents.
⇒ Révolution des tâches : comment l’IA redéfinit le travail au-delà du binaire
Un serveur qui reçoit un appel API et qui dispose de nombreuses capacités
- Il peut interroger un LM.
- Il peut également interroger des systèmes externes et d’autres agents pour répondre aux besoins des utilisateurs.
Prenons un exemple. Imaginons que votre agent de voyage puisse se charger de réserver vos vols, vos hôtels et même gérer vos e-mails lorsque vous êtes en déplacement.
Lorsqu’il voit une opportunité, par exemple des vols bon marché, il procède à la réservation en fonction de vos préférences. Tout cela peut être géré par un agent.
Nexos.ai — Votre Plateforme IA Tout-en-Un
Centralisez l’accès à plus de 200 modèles d’IA avec une seule connexion, sans avoir besoin de multiples abonnements ni d’interfaces différentes.
Optimisez vos coûts : Réduisez les appels d’API redondants, surveillez les requêtes coûteuses et maîtrisez votre budget IA grâce à des outils de gestion intelligents.
💰 Optimisation des coûts
🔒 Sécurité renforcée
🚀 Déploiement facile
Nexos.ai est une plateforme d’orchestration d’IA qui vous permet de rejoindre la révolution IA sans compromettre la sécurité. Testez la plateforme gratuitement et découvrez comment elle peut rationaliser vos opérations IA pour les rendre plus simples, plus économiques et plus efficaces.
L’apprentissage par renforcement
Il s’agit d’une méthode qui permet de former des modèles à se comporter d’une manière particulière.Par exemple, si vous soumettez une requête, une requête utilisateur, au modèle, celui-ci peut générer deux réponses, la réponse 1 et la réponse 2. Vous avez sûrement déjà vu cela dans ChatGPT. Choisissez celle qui vous semble la meilleure.
La réponse choisie obtient un +1, l’autre obtient un -1. Concrètement, vous avez soumis une requête utilisateur. Tout cela peut être représenté par un vecteur, et le vecteur est un espace à n dimensions, donc vous allez à cette coordonnée et vous dites au modèle qu’après être arrivé ici, vous avez généré d’autres jetons, d’autres vecteurs, donc c’est le chemin que vous avez suivi, vous êtes allé d’ici à ici, puis à ici, donc c’était le point final de la réponse et maintenant vous avez obtenu un score de +1, donc cela obtient un score de +1, cela obtient également un score de +1 + 1 + 1 + 1.
Vous pouvez également appliquer des réductions, mais pour l’instant, restons simples. C’est un bon chemin. Vous voulez toujours suivre ce chemin.
La réponse deux était mauvaise. Vous avez suivi ce point jusqu’à ce point, ce point, puis vous vous êtes écarté. Le jeton suivant que vous avez généré après les trois premiers jetons, disons, n’est pas en or. Et puis vous avez mis une virgule ici et vous êtes allé Mais cela peut être le jeton 1 2 3 4. Jeton 1 2 3 4.
Bon, c’était mauvais. Il a obtenu un score de moins 1, ce qui signifie que cette zone obtient un score de moins 1. Cela donne également un score de -1. -1 -1 -1 + 1 donne zéro. -1 + 1 donne 0. – 1 + 1 donne zéro.
Donc, ce que vous faites, c’est que vous avez un espace où vous avez des scores négatifs, des scores positifs et des scores neutres.
Si vous faites cela suffisamment, vous obtiendrez un espace, un espace vectoriel où, étant donné une requête d’entrée, étant donné un point de départ, vous aurez un espace négatif où vous ne voulez pas aller, vous aurez un espace positif où vous voulez absolument aller.
Et plus il est positif, plus vous voulez vous y rendre. D’accord. Vous allez donc peut-être ici. À partir de là, vous avez un autre espace très positif qui se trouve ici. C’est comme une ascension, n’est-ce pas ?
Vous essayez essentiellement d’optimiser le chemin que vous empruntez. En tant que grand modèle linguistique, on s’attend à ce que le résultat final satisfasse l’utilisateur final.
Si l’expérience utilisateur final est bonne, alors le modèle est entraîné pour satisfaire les utilisateurs. C’est ce qu’est l’apprentissage par renforcement avec le retour d’information humain.
Le retour d’information humain vous indique s’il s’agit d’un plus ou d’un moins, et ce retour d’information vous aide à renforcer les bons résultats.
Il s’agit d’une technique extrêmement puissante. En fait, on la retrouve dans la nature.
Si vous connaissez l’expérience du chien de Pavlov, vous savez que Pavlov appuyait sur une cloche et donnait de la nourriture au chien lorsqu’il venait.
Après avoir appuyé sur la cloche, il s’est finalement rendu compte que s’il appuyait simplement sur la cloche sans donner de nourriture, le chien venait déjà et commençait à saliver parce qu’il s’attendait à recevoir de la nourriture. Son comportement a donc été renforcé.
Heureusement, ce n’est pas la seule capacité dont disposent les êtres humains. Vous ne pouvez pas modéliser l’intelligence humaine en utilisant uniquement l’apprentissage par renforcement.
Je vais vous donner un exemple. Imaginons que vous ayez une pièce qui vous donne pile, pile, pile, pile, pile, pile. Si vous savez que cette pièce est équitable, si vous comprenez mentalement comment fonctionne la pièce, que pensez-vous qu’il va se passer ensuite ? Pile ou face ?
Vous ne pouvez pas garantir que ce sera pile la prochaine fois. Mais l’apprentissage par renforcement observe le monde réel et prend une décision en fonction de cela.
Ainsi, lorsqu’il prédit pile, il est renforcé. Bravo. Lorsqu’il prédit face, il est puni. Mauvaise réponse. Mais en réalité, c’est une pièce équitable. Il y a donc 50 % de chances que ce soit l’un ou l’autre.
Si vous demandez à un être humain, que vous lui montrez la pièce, que vous lui dites qu’il s’agit d’une pièce équitable, puis que vous continuez à la lancer, vous obtenez beaucoup de faces, il dira simplement 50/50 car il a une représentation interne du fonctionnement de la pièce.
Il a un modèle mental de la physique de la pièce. L’apprentissage par renforcement ne peut pas construire de modèles mentaux. Il peut simplement vous dire, en se basant sur les résultats, ce qui est le plus probable et ce qui est peut-être la voie la plus avantageuse.
Nous ne sommes pas des crocodiles. Nous sommes des êtres humains. Nous avons une compréhension plus profonde du fonctionnement des choses. Cela dit, l’apprentissage par renforcement est une technique puissante. Il rend les modèles plus intelligents, très intelligents, n’est-ce pas ?
Chaîne de pensée
C’est un concept assez simple, mais très puissant. Lors de l’entraînement du modèle, nous expliquerons clairement notre processus de réflexion ici.
On s’attend à ce que, à mesure que le modèle s’entraîne à résoudre un problème étape par étape, il examine de nouveaux problèmes avec des paramètres différents et soit toujours capable de les raisonner, car il a été entraîné à raisonner étape par étape.
C’est ce qu’on appelle la chaîne de pensée, où le modèle passe par une série de déductions ou d’inférences pour aboutir à la réponse finale. La qualité de cette réponse est généralement bien supérieure à celle d’une réponse directe.
Vous pouvez voir que cela ressemble à quelques invites courtes. La qualité de la réponse est supérieure. Il y a quelques exemples à parcourir. Mais ici, la différence essentielle est qu’il y a une décomposition étape par étape et que de nouvelles étapes peuvent être ajoutées par le modèle s’il le juge nécessaire.
Comme il est entraîné sur une grande quantité de données d’entraînement, il peut être capable de raisonner en ajoutant des étapes supplémentaires à mesure que le problème devient de plus en plus difficile.
En fait, c’est quelque chose qui a été observé par Deepseek. Si vous rendez le problème plus difficile, il passe par plus d’étapes. Si vous rendez le problème plus facile, il passe par moins d’étapes. C’est ce qu’on appelle un modèle de raisonnement (voir sur itforbusiness Les modèles à raisonnement : la nouvelle frontière de l’IA). Bon, ils n’ont pas nécessairement besoin de suivre une chaîne de pensée. Ils peuvent également utiliser d’autres algorithmes.
Par exemple, il existe un arbre de pensée, un graphique de pensée que vous pouvez également parcourir. Vous pouvez également utiliser des outils pour trouver un meilleur raisonnement. Mais un modèle capable de raisonner, un modèle capable de déterminer, à partir d’un problème donné, comment résoudre ce problème étape par étape, est un modèle de raisonnement.
On les appelle aussi LRMS. Bon, des exemples de ça, c’est DeepS et OpenAI, je veux dire les modèles 01 et 03 et d’autres modèles de la série O. Mais il y a des modèles plus récents avec de nouvelles capacités.
Les modèles multimodèles
Bon, l’idée de base, c’est que la plupart des grands modèles linguistiques qu’on connaît fonctionnent sur du texte. Mais qu’en est-il des modèles qui peuvent accepter et créer des images, générer des images ?
Qu’en est-il des modèles qui peuvent accepter et créer des vidéos ? Ils peuvent analyser des images. Ils peuvent vous dire le nombre de pommes dans une image, par exemple, ou ils peuvent modifier une image pour en créer une nouvelle.
De même, pour la vidéo, ces modèles ont des applications formidables, tout comme les grands modèles linguistiques ont changé le domaine du marketing grâce au contenu textuel.
Aujourd’hui, les réseaux sociaux regorgent de contenu issu de grands modèles linguistiques. Les images vont s’améliorer de plus en plus et la vidéo peut devenir un enjeu majeur, car si vous avez des célébrités qui peuvent créer des vidéos, qui peuvent créer des publicités grâce à de grands modèles linguistiques, alors le coût de création d’une vidéo va baisser.
C’est déjà le cas dans une certaine mesure, mais la qualité des modèles n’est pas très bonne. Le terme « multimodèle » désigne en général tout type de mode de saisie de données. Il s’avère que leurs performances sont meilleures que celles des modèles qui sont uniquement entraînés sur du texte.
D’accord, ils ont une compréhension plus approfondie de la signification des objets. Si vous entraînez un modèle sur les chats et les félins, etc., puis que vous lui montrez des images de chats, les performances du modèle et la qualité du résultat sont généralement meilleures. D’accord, l’entraînement est meilleur.
Les trois grands thèmes qui définissent l’orientation de l’IA
Les gens recherchent des modèles plus petits, spécifiques à leur entreprise, des modèles de base. La raison en est que les entreprises veulent avoir plus de contrôle sur ce qu’elles génèrent. Elles veulent également garder les données près d’elles. Elles ne veulent pas les exposer à d’autres entreprises tierces. (à lire sur notre blog Coder en 2026 : obsolète ou indispensable face à l’IA ?)
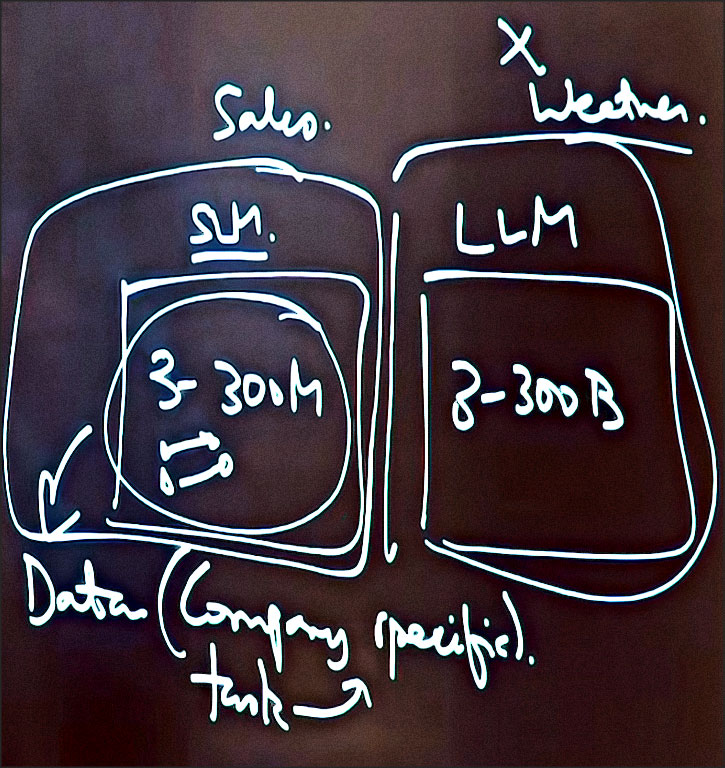
L’une des choses qui se passe actuellement est donc que nous nous intéressons à des modèles plus petits. Les petits modèles linguistiques, comme leur nom l’indique, ont moins de paramètres que les grands modèles linguistiques.
Par exemple, un petit modèle linguistique peut avoir entre 3 et 300 millions de paramètres. D’accord, le réseau neuronal a en interne moins de connexions, moins de poids. Mais si vous regardez les grands modèles linguistiques, en comparaison, vous avez entre 3 et 300 milliards de paramètres. D’accord ? Il y a donc un très grand réseau neuronal avec beaucoup de poids dans un LLM, mais un SLM est plus petit.Mais ils sont utiles car ils sont entraînés sur moins de données, qui peuvent être spécifiques à une entreprise ou à une tâche.
Par exemple, un bot qui est entraîné uniquement sur les requêtes des clients, la manière de gérer les requêtes des clients, la manière de réaliser des ventes, est susceptible de fonctionner correctement. Il sera expert en vente, mais il ne pourra probablement pas vous fournir une analyse météorologique détaillée pour la plupart des entreprises. Cela n’a pas d’importance.
Dans le cas de la NASA, c’est ce dont vous avez besoin. Vous ne vendez probablement rien. Espérons que ce soit le cas. Qui sait ? Mais la NASA serait plus intéressée par la création d’un modèle de base capable de prédire la météo, sans se soucier de la partie commerciale.
Ainsi, les modèles linguistiques plus petits sont formés par les entreprises à partir de leurs données spécifiques et propriétaires afin de fournir des réponses raisonnablement bonnes pour des cas d’utilisation spécifiques.
Le processus de création de petits modèles linguistiques : La distillation
L’idée de base est que vous disposez d’un grand modèle linguistique qui sert de professeur, puis vous lui transmettez certaines données.
Vous examinez le résultat du grand modèle linguistique et, en parallèle, vous l’envoyez également à un petit modèle linguistique. Celui-ci, qui comporte moins de paramètres, tente également de prédire le résultat.
Le professeur produit donc une sortie et l’élève essaie d’imiter le professeur. Si ces deux sorties correspondent, cela signifie que le petit modèle linguistique fonctionne bien. Aucun poids n’a besoin d’être modifié.
Mais s’il ne fonctionne pas bien, les poids internes du petit modèle linguistique sont modifiés. Cependant, le nombre de poids attribués à ce modèle est limité, entre 3 et 300 millions. Ce que vous essayez essentiellement de faire, c’est de condenser ces informations du réseau neuronal complexe en une représentation aussi raisonnable que possible, de manière à ce que vos performances soient correctes, mais que les coûts soient considérablement réduits.
Ainsi, pendant le temps d’exécution, lors de l’inférence de production, lorsque vous recevez une requête, la réponse sera beaucoup plus rapide qu’avec ce grand modèle linguistique. De plus, il est également plus facile à héberger.
Les modèles distillés nous amènent au dernier terme que vous devez absolument connaître si vous êtes ingénieur, à savoir la quantification
L’idée ici est que vous disposez de réseaux neuronaux. Chacun de ces poids est essentiellement un nombre. Disons un nombre de 32 bits. Et si vous pouviez prendre ces poids et condenser ces informations en 8 bits ? Vous pourriez alors économiser 75 % de votre mémoire.
Cela ne s’applique pas directement ici, car les poids sont généralement calculés uniquement sur le réseau neuronal à propagation directe. Vous disposez toujours du mécanisme d’attention et le coût de formation reste le même, car au départ, vous obtenez un très bon modèle sans quantification.
Une fois le modèle entièrement formé, vous appliquez la quantification. Le coût de formation ne diminue donc pas. Cela sert principalement à réduire le coût de l’inférence ou, pendant la production, le coût d’exécution d’un modèle.
Voici donc les 20 termes les plus importants que je souhaite aborder dans le domaine de l’ingénierie de l’IA. Je pense que la connaissance de ces termes vous aidera à communiquer efficacement avec tout autre ingénieur en IA ou les membres de votre équipe.
Je n’ai pas pu entrer suffisamment dans les détails ici, car quand on parle du mécanisme d’attention ou du cache KV, on ne peut pas le faire dans un article de seulement 2000 mots. Mais ce que vous devez savoir, ce sont ces termes et la plupart des choses que j’ai mentionnées dans le cours d’ingénierie IA de Interview Ready.
Si vous les connaissez, vous comprenez vraiment comment ces modèles fonctionnent et tout le battage médiatique et les absurdités qui circulent dans ce domaine, et cela vous semble alors ridicule, n’est-ce pas ? Vous êtes en mesure de mieux les reconnaître.
Merci d’avoir lu cet article. J’espère qu’il vous a plu. À la prochaine fois.
Questions fréquentes
Quelle est la différence entre un transformateur et un grand modèle linguistique ?
Un grand modèle linguistique (LLM) est un système qui prédit le prochain token d’une séquence, tandis qu’un transformateur est l’algorithme ou l’architecture spécifique, utilisant des mécanismes d’attention et des réseaux feed-forward, que de nombreux LLM utilisent pour effectuer cette prédiction.
Comment la tokenisation aide-t-elle les grands modèles linguistiques à comprendre le langage humain ?
La tokenisation divise le texte saisi en unités plus petites appelées tokens, qui peuvent être des mots entiers, des sous-mots ou même des caractères. Cela permet au modèle de traiter des schémas linguistiques tels que les suffixes courants (par exemple, « -ing » ou « -ers ») et de mieux comprendre la structure et le sens du langage naturel.
Quel est l’objectif du réglage fin d’un modèle linguistique de grande taille ?
Le réglage fin adapte un modèle de base pré-entraîné afin qu’il fonctionne bien pour des tâches ou des domaines spécifiques, tels que le diagnostic médical ou l’analyse financière, en l’entraînant davantage sur des paires de questions-réponses ciblées, ce qui permet de rendre ses réponses plus précises et plus appropriées au contexte.
Pourquoi les bases de données vectorielles sont-elles importantes dans les applications d’IA ?
Les bases de données vectorielles stockent du texte ou des données sous forme de vecteurs sémantiques et permettent des recherches rapides par similarité. Cela permet aux systèmes de récupérer les documents ou les informations les plus pertinents contextuellement en réponse à une requête utilisateur, ce qui est essentiel pour des techniques telles que la génération augmentée par la recherche (RAG).
Quel rôle joue l’apprentissage par renforcement dans l’amélioration des réponses de l’IA ?
L’apprentissage par renforcement avec rétroaction humaine (RLHF) forme les modèles en récompensant les résultats souhaités et en pénalisant ceux qui ne le sont pas. Au fil du temps, cela façonne le comportement du modèle afin qu’il s’aligne davantage sur les préférences humaines, améliorant ainsi la qualité et l’utilité des réponses.
Références
Sources fiables
Attention Is All You NeedAuteur : Ashish Vaswani et al. – Publié en : 2017 |
Language Models are Few-Shot LearnersAuteur : Tom B. Brown et al. – Publié en : 2020 |
Training a helpful and harmless assistant with reinforcement learning from human feedbackAuteur : Auteur non spécifié – Publié en : 2022 |
Distilling the Knowledge in a Neural NetworkAuteur : Geoffrey Hinton, Oriol Vinyals, Jeff Dean – Publié en : 2015 |
Références de mon blog
Coder en 2026 : obsolète ou indispensable face à l’IA ?Auteur : Moi-même – Publié le : 08 novembre 2025 |
Révolution des tâches : comment l’IA redéfinit le travail au-delà du binaireAuteur : Moi-même – Publié le : 06 août 2025 |
