
Parfois il est bon, sur internet, de savoir comment faire pour remonter le temps. J’entends par là : savoir à quoi ressemblait un site internet donné il y a un jour, une semaine, un mois, un an ou dix ans en arrière.
Durant ce laps de temps, le site a pu disparaître, a pu être transformé.
Pour les référenceurs, savoir à quoi ressemblait un site avant sa disparition a un autre intérêt :
Losque vous tombez sur un site concurrent au vôtre qui n’existe plus sur internet mais qui avait à l’époque une forte influence, il y a de fortes chances pour qu’il possède encore une tonne de backlinks (des liens qui pointaient vers lui) qui ne servent plus à rien et qui renvoient maintenant à une erreur 404.
Si vous tombez sur ce genre de perle rare, il est bon que vous puissiez savoir à quoi il ressemblait afin de pouvoir le copier ou proposer aux webmestres qui pointaient vers lui une alternative : autrement dit, proposez-leur alors votre propre site qui bénéficiera alors de backlinks supplémentaires.
Cette technique est très efficace en terme d’autorité.
Pour savoir à quoi ressemblait un site avant sa disparition, rendez-vous sur The Wayback Machine à cette adresse : http://archive.org/web.php.
Rentrez l’adresse en question et vous tombez sur un genre de calendrier.
En 2010, par exemple, Des Geeks et des lettres ressemblait à ça :
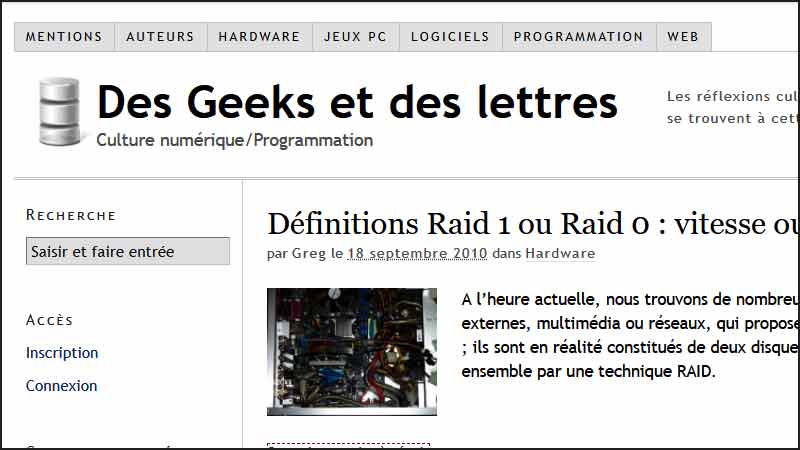
=> Ici pour voir le site Des Geeks et des lettres en 2010 <=
Comme je l’ai précisé, cette technique a un grand intérêt en SEO pour savoir comment remplacer une page web bourrée de backlinks. Mais elle peut aussi intéresser tout webmestre curieux de connaître l’évolution d’un site donné.
Rares sont les sites qui n’ont jamais été crawlés par les robots de archive.org.
mdr oui c’est une façon sympathique d’utiliser ce service 😀
J’ai essayé le trucs mais plutôt pour voir un peu avec nostalgie mes sites préférés dans le temps. Je prends plaisir relire certains de mes commentaires sur des blogs, comme j’ai pu être con ! 🙂