Dans cet article, nous allons voir ce que sont les modèles basés sur la diffusion. Ceux-ci remplacent rapidement les grands modèles linguistiques pour la plupart des tâches.
- Génération de code,
- génération d’images,
- génération de vidéos.
À la fin de cet article, vous saurez ce qu’est un modèle basé sur la diffusion, en quoi il est utile et quel est le mécanisme interne utilisé par un modèle de ce type.
Commençons par comprendre les modèles basés sur la diffusion. Voyons comment ils génèrent des résultats. Une requête d’entrée pourrait être : quel sera le meilleur langage de programmation en 2026 ?
Si vous disposez d’un modèle linguistique volumineux, il pourrait répondre, en termes de popularité, à Python. Le grand modèle linguistique va générer des jetons un par un, de gauche à droite. Mais si vous prenez en compte un autre critère, par exemple la vitesse, vous diriez peut-être Rust et Go, ce qui signifie que le résultat final, c’est-à-dire les jetons, dépend entièrement du fait que vous ayez choisi la popularité.
Si nous transmettons la même entrée à un modèle basé sur la diffusion, celui-ci va générer un ensemble de jetons. Le modèle de diffusion peut désormais améliorer de manière itérative ce résultat en remplaçant certains des jetons. Ainsi, en termes de vitesse, je peux passer à la sécurité, je choisis C++ et il peut affiner encore davantage sa réponse en ajoutant les jetons de et vitesse.
S’il s’agissait d’un modèle linguistique de grande taille, après avoir généré le jeton de sécurité, vous n’auriez d’autre choix que de suivre cette idée initiale. Mais pour un modèle basé sur la diffusion, il n’y a pas de telle contrainte. Il peut générer du texte en faisant des allers-retours jusqu’à ce que vous obteniez quelque chose d’acceptable.
Pourquoi est-ce si utile ?
Pensez aux images que vous générez. Si vous allez de gauche à droite pendant la génération d’une image, il est fort probable que vous ayez fait une erreur ici ou là. Mais dans un modèle autorégressif, vous ne pouvez pas vraiment améliorer cela.
Dans le cas d’un modèle basé sur la diffusion, comme l’image entière est constamment améliorée, vous pouvez améliorer l’image jusqu’à ce qu’elle devienne acceptable. C’est le comportement d’un modèle basé sur la diffusion.
Mais pourquoi est-il si populaire ?
Est-il vraiment meilleur qu’un grand modèle linguistique ? Dans de nombreux cas, non. Les grands modèles linguistiques ou les modèles autorégressifs ont notamment l’avantage de nécessiter moins de puissance de calcul.
Si vous achetez de nombreux GPU Nvidia et que vous avez presque épuisé votre budget, il est logique d’opter pour un modèle autorégressif qui nécessitera moins de puissance de calcul qu’un modèle basé sur la diffusion. Cependant, à l’heure actuelle, en ce qui concerne 2025 ou au-delà, il semble que le principal obstacle à la mise à l’échelle des modèles ne soit pas la puissance de calcul, mais les données.
Les données sont considérées comme le combustible fossile du monde
Les données sont considérées comme le combustible fossile du monde, dans le sens où leur production est limitée et prend beaucoup de temps. Il est encore plus difficile d’extraire des informations de ces données, car beaucoup d’entre elles sont répétitives.
Par exemple, si je dispose de prévisions météorologiques et que je vous donne les prévisions de 37 °C, 38 °C, 30 °C, 31 °C, toutes ces données m’indiquent simplement que cet endroit est chaud.
La quantité de données dont nous disposons dans le monde est faible
La quantité que nous générons n’est pas non plus très importante. Nous sommes capables de calculer beaucoup plus que ce que nous générons. Et la quantité d’informations que vous obtenez avec toutes ces données est limitée.
Sachant cela, les modèles basés sur la diffusion présentent un avantage évident. L’un d’entre eux est que, pour une même quantité de données, les modèles de diffusion surpassent les modèles autorégressifs.
L’autre avantage est que si vous transmettez les données à plusieurs reprises pendant l’entraînement, par exemple quatre fois pour un modèle autorégressif, celles-ci sont alors presque considérées comme des données nouvelles par le modèle autorégressif.
La raison en est qu’une fois que vous avez transmis ces données à votre réseau neuronal, celui-ci va mettre à jour ses poids. La deuxième fois que vous transmettez les données, certains poids peuvent être inexacts ou incorrects, ou avoir été trop modifiés.
Vous avez donc l’époque 1, puis l’époque 2, jusqu’à l’époque 4. Les mêmes données peuvent être réutilisées, il suffit de les renvoyer en double.
D’autre part, vous avez le modèle basé sur la diffusion qui peut avoir des doublons 100 fois, pas quatre fois, mais 100 fois. C’est la principale raison pour laquelle, en tant qu’ingénieur en IA, vous vous intéressez à un modèle basé sur la diffusion : vous manquez de données et, pour obtenir le meilleur retour sur investissement possible avec les données limitées dont vous disposez, vous vous tournez vers la diffusion.
Comment fonctionnent réellement les modèles basés sur la diffusion
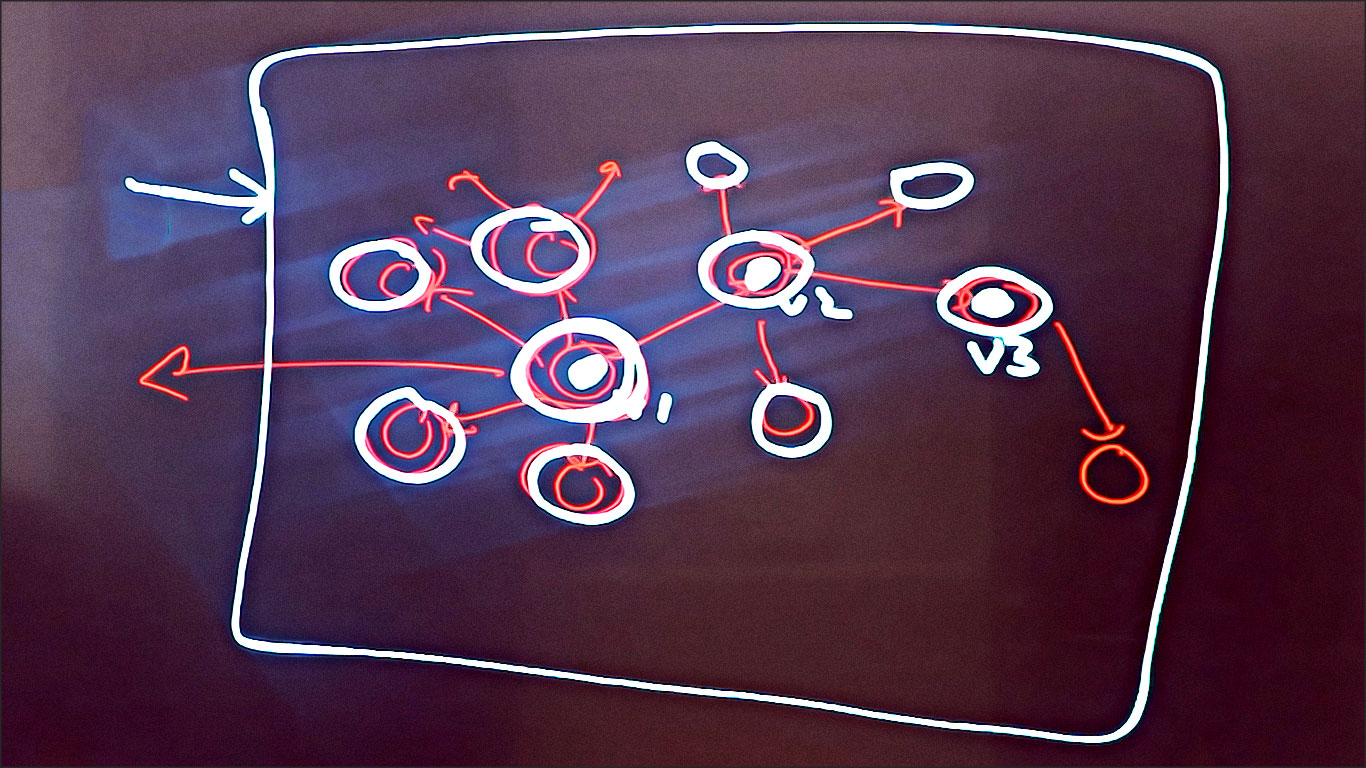
Tout d’abord, vous disposez d’une sorte d’entrée qui peut être une image, un code ou une vidéo pour le modèle. Le modèle mappe cette entrée dans un vecteur. S’il s’agit d’une image, ce sera un vecteur image. S’il s’agit d’une vidéo, ce sera un vecteur vidéo, et ainsi de suite. Le vecteur est alors essentiellement une cartographie dans un espace à n dimensions.
Le modèle prend l’entrée d’origine, puis y ajoute du bruit, ce qui place le vecteur dans une nouvelle position. Disons qu’il s’agit de v_sub_1. Ce sera v_sub_2 pour l’image bruyante. Vous pouvez ensuite y ajouter davantage de bruit pour le déplacer vers une nouvelle position v_sub_3.
Et de cette manière, vous continuez à ajouter du bruit jusqu’à ce que l’entrée d’origine soit presque complètement déformée. Il y a alors très peu d’informations disponibles.
S’il y a très peu d’informations disponibles, alors ce vecteur que vous pouvez cartographier dans l’espace vectoriel n’a que très peu de sens.
Vous obtenez un ensemble de vecteurs en ajoutant de plus en plus de bruit. En fait, pour être plus précis, vous prenez l’image originale v1 et vous la mappez sur plusieurs vecteurs proches.
Ensuite, vous prenez l’image bruyante, la première couche d’images bruyantes, et vous y ajoutez encore plus de bruit, ce qui signifie qu’elles s’éloignent de plus en plus de la première image la plus significative.
Vous obtenez ainsi un espace vectoriel avec une seule image, qui a une valeur élevée ici, proche de la réalité. Une valeur légèrement inférieure ici, ici, ici, ici et ici. Et une valeur beaucoup plus faible ici, ici, ici et ici.
Ainsi, la première image originale a une valeur très élevée. On peut dire qu’elle a un score de 1 000. La deuxième a un score de 100. Le troisième niveau d’image bruyante a un score de 10. Et peut-être que le quatrième niveau a un score de 1.
Tu en as marre des IA qui te censurent à chaque phrase ?
J’ai switché sur uncensored.com (Claude + Gemini 100 % sans filtre). Je l’utilise tous les jours pour mes articles.
→ Accéder à l’IA vraiment libre (30 % off + 7 jours gratuit)Ceci concerne une seule image. Une autre image pourrait apparaître ici, ce qui rendrait ce point très important.
Vous pouvez imaginer qu’une nouvelle école s’installe dans un quartier. Le prix de tout ce qui se trouve dans cet endroit augmente. Dans un modèle basé sur la diffusion, si un nouvel échantillon arrive, il y a une certaine réalité que ce vecteur représente réellement. Ainsi, tous les points proches de cet endroit, après y avoir ajouté du bruit, ont une valeur ajoutée.
Dans un espace tridimensionnel, il s’agira de montagnes, de collines plus petites et de petits monticules. Tout le reste est plat. Et votre travail, lorsque vous êtes plongé dans cet espace 3D, consiste à trouver la plus haute montagne que vous pouvez voir.
Le modèle basé sur la diffusion contient donc de très nombreuses images, des centaines de milliers d’images qui y sont intégrées. Il génère ensuite cet espace n-dimensionnel complexe où les valeurs élevées sont représentées par des vecteurs directs et où la valeur continue de diminuer à mesure que vous ajoutez de plus en plus de bruit aux images originales.
La génération de texte ou de tout autre type de sortie est intuitive
Nous savons que l’espace de valeur la plus élevée est celui vers lequel nous devons nous diriger. Nous sommes poussés vers cet espace par la requête d’entrée. Et nous itérons lentement vers une meilleure solution en utilisant la descente de gradient. Nous suivons essentiellement un chemin vers le point de valeur maximale.
C’est ainsi que vous pouvez générer une sortie pour n’importe quelle requête d’entrée donnée.
La requête peut également être une image. Générez une image qui ressemble à cette image. C’est possible. Générez un code qui ressemble à ce code ou générez-moi un code à partir de ma requête textuelle. Vous allez prendre cette requête textuelle et disposer d’un mécanisme pour la convertir en vecteur.
La seule question qui reste est de savoir comment ces vecteurs sont générés. Lorsqu’on nous donne une image, un morceau de code ou un fichier vidéo, comment le mapper dans un espace vectoriel ? La réponse est un auto-encodeur variationnel, qui semble beaucoup plus complexe qu’il ne l’est en réalité. Il s’agit en fait d’un moteur de compression.
À partir d’un objet donné, vous pouvez le hacher pour obtenir un seul nombre, une seule valeur. Un auto-encodeur variationnel prendrait le même objet et le hacherait pour obtenir une valeur ayant une signification sémantique.
L’idée serait que si vous prenez différentes images de chats et que vous les passez dans un auto-encodeur variationnel, la valeur de hachage ou le résultat final sera tel que dans l’espace vectoriel, tous les points correspondant aux chats, les points à n dimensions que nous avons générés pour les chats, seront proches les uns des autres. Ceux correspondant aux chiens pourraient également être proches, car après tout, ce sont aussi des animaux. Les arbres pourraient être assez éloignés les uns des autres.
Cet auto-encodeur variationnel est donc capable de compresser l’image à sa représentation minimale. Comment est-il entraîné ? Vous lui transmettez l’image d’un chat, puis vous essayez de la régénérer. C’est le meilleur test pour un moteur de compression. Vous lui transmettez l’image originale, puis vous essayez de reconstruire cette image originale.
Si vous y parvenez de manière satisfaisante, vous pouvez alors affirmer que ce moteur de compression est performant. La représentation intermédiaire ne perd aucune information. Ces vecteurs sont donc générés à l’aide d’auto-encodeurs variationnels.
Les nouveaux modèles de Google effectuent désormais une génération de vecteurs de bout en bout
Vous n’avez donc pas besoin de former séparément un VAE. Vous pouvez en fait créer ce modèle de diffusion dans cet espace et, pendant sa création, les vecteurs sont également mis à jour. Cette fonctionnalité est intégrée au processus de formation par diffusion.
Les modèles de diffusion sont supérieurs aux modèles autorégressifs en termes d’efficacité des données et sont donc largement utilisés pour générer des images, des vidéos et, plus récemment, du code. À l’avenir, lorsque nous serons à court de données, que nous aurons de moins en moins de données à exploiter et à utiliser pour l’entraînement, je pense que les modèles basés sur la diffusion gagneront encore en popularité.
- Ils ne sont pas plus intelligents.
- Ils ne sont pas plus performants que les grands modèles linguistiques dont nous disposons aujourd’hui.
- C’est simplement que leurs performances, leurs benchmarks, sont meilleurs.
Il y a une différence fondamentale. L’architecture interne ne les rend pas plus intelligents. C’est simplement que leurs performances sur les benchmarks limités dont nous disposons actuellement sont supérieures.
Questions fréquentes
Quel est le principal avantage des modèles de diffusion par rapport aux grands modèles linguistiques autorégressifs ?
Les modèles de diffusion peuvent générer et affiner de manière itérative l’ensemble de la sortie en une seule fois en remplaçant des tokens ou des pixels, tandis que les modèles autorégressifs génèrent des tokens de manière séquentielle de gauche à droite et ne peuvent pas revenir en arrière pour corriger les erreurs précédentes.
Pourquoi les modèles de diffusion deviennent-ils plus populaires en 2025 et au-delà ?
Le principal obstacle à la mise à l’échelle des modèles n’est plus le calcul, mais les données. Les modèles de diffusion sont beaucoup plus efficaces en termes de données et peuvent réutiliser efficacement les mêmes données des centaines de fois, alors que les modèles autorégressifs perdent la plupart de cet avantage après quelques époques.
Comment les modèles de diffusion fonctionnent-ils réellement en interne ?
Ils mappent les entrées à des vecteurs dans un espace à haute dimension, ajoutent progressivement du bruit jusqu’à ce que le signal ait presque disparu, créant ainsi un paysage de « montagnes » où les points de données réels sont des pics. La génération commence à partir du bruit et grimpe jusqu’au pic le plus proche en utilisant la descente de gradient ou l’échantillonnage.
Quel rôle jouent les auto-encodeurs variationnels dans les modèles de diffusion ?
Ils compressent les images, le code ou la vidéo en vecteurs latents significatifs qui préservent la proximité sémantique (les chats près des chats, les chiens près des chiens). Les modèles plus récents intègrent cette compression directement dans le processus d’entraînement par diffusion.
Les modèles de diffusion sont-ils réellement plus intelligents que les grands modèles linguistiques ?
Non, ils ne sont pas plus intelligents. Ils obtiennent simplement de meilleurs résultats avec moins de données grâce à une meilleure efficacité des données. L’architecture en elle-même ne les rend pas plus intelligents.
Références
Sources fiables
Auto-Encoding Variational BayesAuteur : Diederik P. Kingma et Max Welling – Publié en : 2013 |
Denoising Diffusion Probabilistic ModelsAuteur : Jonathan Ho, Ajay Jain et Pieter Abbeel – Publié en : 2020 |
Diffusion Models Beat GANs on Image SynthesisAuteur : Prafulla Dhariwal et Alex Nichol – Publié en : 2021 |
Diffusion Models: A Comprehensive Survey of Methods and ApplicationsAuteur : Ling Yang et al. – Publié en : 2022 |
Références de mon blog
Tous nos articles sur l’intelligence artificielleAuteur : Des Geeks et des Lettres |