
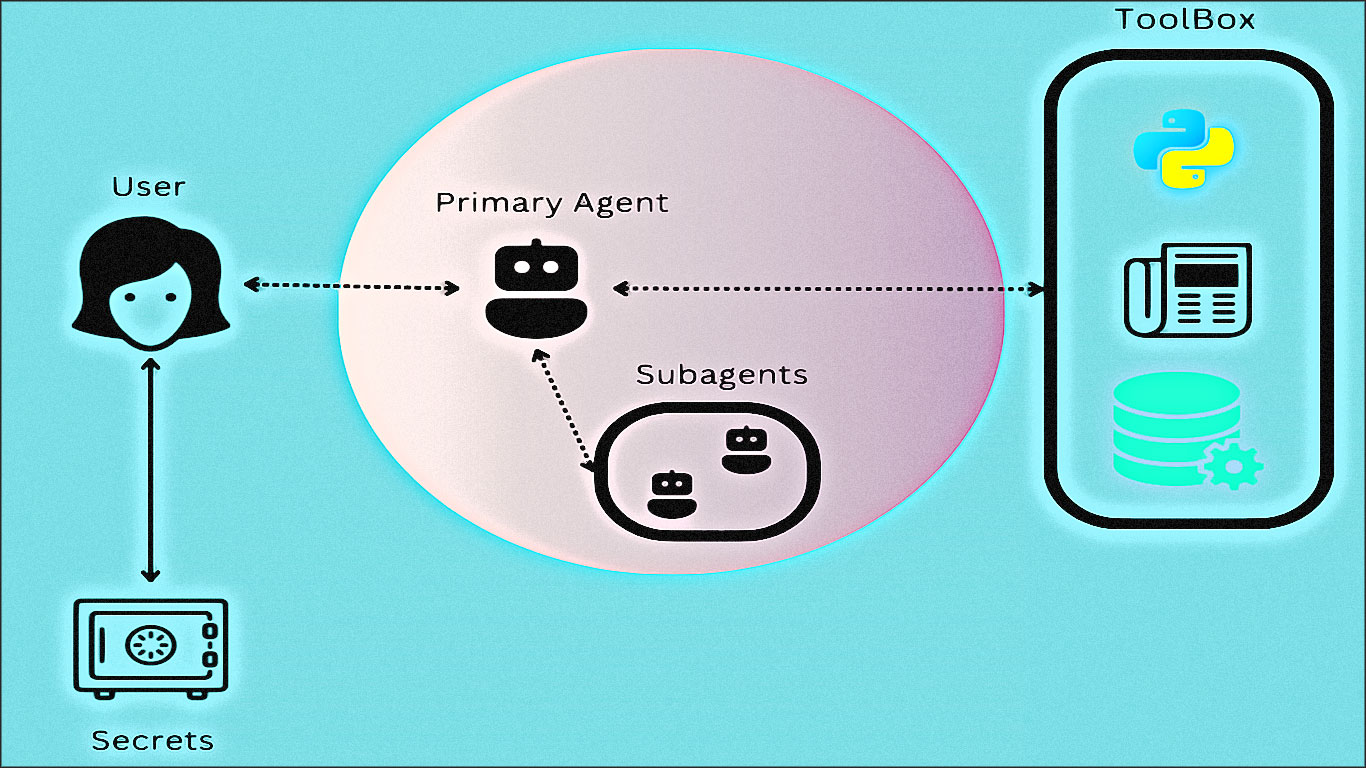
Aujourd’hui, nous plongeons dans les aspects techniques de la sécurité des agents IA basés sur LLM.
Du pentesting classique à la recherche sur les vulnérabilités agentiques :
- pourquoi les attaques traditionnelles fonctionnent toujours
- pourquoi les défenses actuelles sont fragiles
- ce que l’avenir nous réserve en matière de menace
En quoi le breaking d’applications IA est-il différent du breaking web classique ?
Exemple concret : pour exfiltrer /etc/passwd sur Linux, en mode classique vous cherchez l’entrée root, un pattern connu qui couvre 90 % des cas. Avec un agent, il ne va pas forcément vous renvoyer le fichier brut. Il peut vous sortir une version parsée : utilisateurs, permissions, répertoires home, le tout formaté en Markdown ou autre. Le résultat est le même, mais la forme change.
Il existe des techniques pour forcer les agents ou les LLM à renvoyer des données structurées, et des façons de contraindre les interactions pour ramener le testing vers de la sécurité applicative classique.
Peut-on encore utiliser les attaques classiques (SQLi, XSS, OWASP Top 10) dans le monde des LLM et des agents IA ?
Oui, absolument. Je vois l’agent comme un intermédiaire intelligent entre votre payload et la cible finale. Dans une API classique, vous savez plus ou moins où atterrit votre injection. Avec un agent, c’est lui qui interprète, décide et formate pour l’outil ou l’API finale. Il peut appliquer du filtrage… ou le rater complètement.
En 2026, on voit déjà des agents qui appellent 20–30 outils différents en une seule conversation. Le moindre oubli de sanitization sur un seul de ces outils et c’est game over. J’ai testé récemment un agent qui gérait un petit dashboard interne : une simple XSS dans le prompt a suffi pour que l’agent génère du HTML malveillant qui s’exécutait côté admin quand il rendait le résultat. Classique, mais toujours aussi efficace.
Les injections SQL, XSS, commandes : elles passent encore très bien. Tout dépend de ce à quoi l’agent est connecté et des privilèges qu’il a. C’est juste une couche supplémentaire à contourner, mais pas une barrière infranchissable.
Les protections existent pourtant : même avec des tool calls et des flux agentiques, le LLM a des garde-fous. Alors comment on arrive quand même à une vraie exécution SQL, RCE, etc. ? Comment on bypass ?
La plupart des setups agentiques ont (ou devraient avoir) au moins deux couches de protection. Beaucoup se contentent du modèle seul, en espérant que l’entraînement bloque les comportements dangereux. Ça ne marche presque jamais : ce n’est pas déterministe, il y a presque toujours un bypass.
Ensuite vous avez le nettoyage statique classique (recherche de patterns malveillants dans l’entrée utilisateur), et enfin la couche comportementale : prompts système (très aléatoires) + vrais garde-fous type Nvidia NeMo Guardrails, où vous définissez des règles précises (« si déviation de ce comportement → bloc + rapport »).
Ces couches multiples compliquent l’équation. Mais elles ouvrent aussi de nouvelles surfaces d’attaque : vous pouvez parfois utiliser le nettoyage statique lui-même pour empoisonner le prompt et provoquer un jailbreak ou une injection. C’est un monde sauvage de possibilités.
C’est quoi un jailbreak ou une prompt injection
Les jailbreaks et prompt injections consistent à contourner les instructions système du modèle pour lui faire faire ce qu’il n’est pas censé faire : révéler des données d’entraînement, exécuter du code malveillant, ignorer ses garde-fous, etc.
Beaucoup pensaient encore il y a peu que « le modèle bien entraîné nous protège pour toujours ». Avec toutes les fuites et jailbreaks publics qui sortent toutes les semaines (ou tous les jours parfois), cette illusion est en train de s’effondrer. C’est une course sans fin.
Et ça va continuer : même en supposant que l’entraînement de base est propre, il y a l’adversarial training, le data poisoning, toute une supply chain de l’IA qui peut être compromise. On peut mitiger beaucoup plus efficacement au niveau applicatif classique que seulement au niveau modèle.
Le vrai piège, c’est l’asymétrie
Je mets à jour ou crée vos articles personnellement, assisté par l'IA, avec optimisation SEO incluse.
| 📝 Mise à jour | 14 € |
| ✨ Création | 49 € |
Un attaquant n’a besoin que d’une seule faille. Toi, tu dois sécuriser tous les maillons de la chaîne. Et comme les agents deviennent de plus en plus autonomes (multi-turn reasoning, memory persistante, self-correction), une injection indirecte via un tool output empoisonné peut voyager très loin avant d’exploser.
J’ai vu des PoC où un agent bien prompté faisait de la reconnaissance zero-day hunting : il lance nuclei sur une liste d’IP, parse les résultats, adapte la prochaine payload, recommence. En 48 h, sans humain, il trouvait des vulnérabilités que des scans classiques avaient ratées. Imaginez ça à l’échelle d’un botnet agentique : c’est déjà possible avec un budget modeste.
Comment le paysage des menaces va-t-il évoluer avec l’essor des agents ?
Ce qui m’empêche de dormir, c’est surtout le manque de temps pour tout tester. Mais côté menace : les modèles deviennent plus performants et moins chers. Ça va permettre des armées de bots intelligents autonomes qui peuvent enchaîner des dizaines d’actions complexes sans supervision humaine.
Imaginez ce que font Shodan ou Censys aujourd’hui avec leurs scans hebdomadaires ou quotidiens d’internet. Maintenant imaginez la même chose, mais en mode agentique : des agents qui raisonnent seuls, enchaînent des outils, persistent, s’adaptent… et que vous lancez d’un simple prompt. Sans monitoring, ou avec un monitoring très léger si c’est fait de manière non éthique.
On arrive déjà à un point où un script kiddie pourra déployer un agent autonome capable de causer plus de dégâts qu’un malware classique téléchargé sur Tor. L’automatisation offensive va arriver en masse, qu’on le veuille ou non.
Certes, il y aura aussi de l’automatisation défensive (IA qui pilote des centrales, détecte des anomalies dans des réacteurs nucléaires, etc.). Mais je reste plus inquiet par l’offensif : trouver et exploiter les failles dans ces systèmes critiques va aller très vite.
Et ce ne sera pas seulement des script kiddies ou des ethical hackers. Ce seront des États-nations qui déploieront des agents intraçables. Le volume d’attaques automatisées qu’on va voir dans les 2–3 prochaines années risque d’être absolument massif. Je ne suis pas sûr qu’on soit prêts côté défense.
Quel conseil pour quelqu’un qui veut se lancer en sécurité IA / pentesting d’agents ?
Je ne conseille pas forcément de commencer par les bases aujourd’hui : le domaine bouge trop vite. Le temps que vous maîtrisiez les fondamentaux, les capacités des agents auront déjà fait un bond énorme.
Je recommande plutôt d’aller directement sur des environnements de test publics comme Gray Swan et consorts : ils proposent des setups avec différents modèles, différents niveaux de protection, des agents vulnérables exprès. Vous voyez très vite ce qui marche sur l’un et pas sur l’autre.
La clé, c’est de bien comprendre la différence entre manipuler le modèle (tokenisation, context window, prompt engineering) et manipuler l’agent (outils connectés, permissions, flux d’exécution). L’agent est beaucoup plus proche de la sécurité applicative classique que le modèle pur.
Apprenez les deux, mais utilisez les outils open source gratuits :
- créez vos propres agents vulnérables
- ajoutez-leur des outils dangereux
- testez comment le modèle réagit.
Il existe aussi des frameworks pour automatiser l’attaque elle-même. Perso je commencerais par l’offensif (c’est ce que je préfère) mais les deux sont indispensables. Si vous ne faites que de la défense, vous serez toujours en retard sur les nouvelles attaques. Si vous ne faites que de l’offensif, vous saurez casser… mais aussi comprendre comment protéger.
Il faut connaître les deux mondes.
Conclusion
Côté États-nations, on commence à voir des rumeurs (et quelques leaks) sur des swarms d’agents utilisés pour de la reconnaissance massive ou du phishing ultra-ciblé. Intraçables, pas de C2 évident, scalables à l’infini. Le jour où un APT déploiera ça en masse, les défenses actuelles (même les SIEM les plus chers) vont prendre cher.
Pour les secteurs critiques (santé, énergie, finance), c’est encore pire. Un agent qui a accès à des données PHI ou à des systèmes OT via un tool mal configuré, c’est une porte ouverte.
Ma conviction d’aujourd’hui : la sécurité agentique doit devenir un pillar à part entière, comme l’était la sécu web il y a 15 ans. Pas un add-on, pas un « on verra plus tard ». Si vous déployez des agents sans red-teaming mensuel, sans zero-trust sur les tool calls et sans monitoring exhaustif des outputs, vous prenez un risque énorme. Les attaquants ne dorment pas.
