

La fenêtre contextuelle d’un million de jetons était censée améliorer les choses, mais elle les a en réalité aggravées.
Ce qui nous a poussés à creuser plus loin que les conseils habituels : le code source de Claude Code a été rendu public, et ce qu’on y a trouvé explique pourquoi vos tokens fondent comme neige au soleil, et ce n’est pas forcément de votre faute. La plupart des guides sur le sujet vous répètent les mêmes astuces de surface, mais personne ne parle des fuites de tokens enfouies dans le code lui-même ni des flags de configuration que presque personne n’utilise.
C’est pourquoi nous avons recherché les optimisations les plus efficaces pour réduire les tokens Claude Code et faire durer vos sessions plus longtemps.
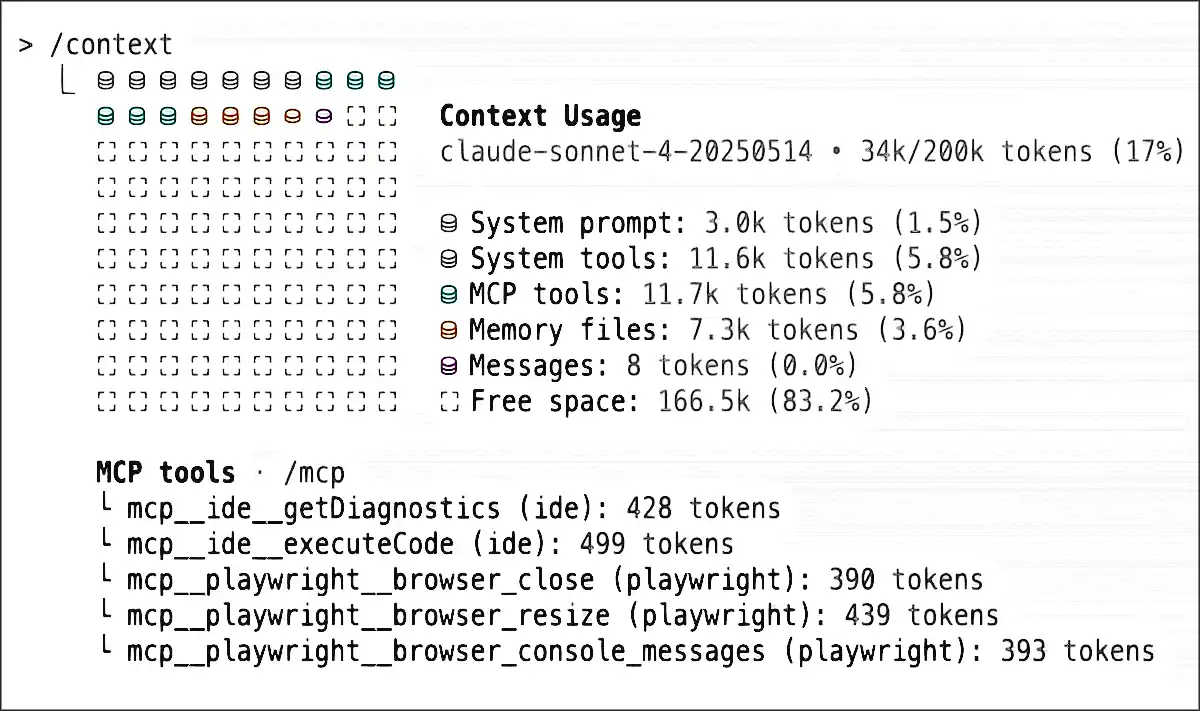
Comment fonctionnent les limites de messages Claude
Claude propose 2 forfaits payants, Pro et Max. Max est le plus cher, Pro coûte 20 $ par mois. Les deux donnent accès à Claude Code, Co-work et d’autres fonctionnalités absentes du forfait gratuit, mais ils suivent la même règle : un nombre limité de messages par fenêtre de 5 heures, puis réinitialisation.
La fenêtre de 5 heures démarre à votre premier message, que ce soit sur le bureau, le web ou n’importe quelle interface Claude. Une fois ouverte, chaque message est comptabilisé.
La fenêtre ne dépend pas non plus de l’appareil. Multi-appareils avec le même compte = même limite.
Pour le forfait Pro, vous recevez environ 45 messages par fenêtre de 5 heures. Max en donne 225, et Max 20x (plus cher que le forfait à 100 $) en offre 900. Ces chiffres varient selon le modèle : plus de messages avec Sonnet, moins avec Opus.
Pourquoi 45 messages ne suffisent parfois pas pour une session Pro ?
Ce n’est qu’un décompte approximatif. Le modèle utilisé joue beaucoup : Opus consomme trois fois plus de tokens que Sonnet pour la même requête, car il est nettement plus puissant et gourmand en calcul. Le type de tâche aussi — les tâches gourmandes en calcul ou nécessitant plusieurs outils brûlent des tokens à vitesse grand V. Et Anthropic a réduit la limite de session plus rapidement pendant les heures de pointe, lorsque le service est sous forte pression. Résultat : votre quota peut fondre bien avant les 45 messages annoncés.
Les fuites cachées de tokens dans le code source de Claude Code
Le code source de Claude Code a été rendu public, et plusieurs problèmes ont été identifiés : des bugs qui font que vos limites s’épuisent plus vite que ce que les chiffres officiels laissent entendre.
L’un d’eux concerne les réponses tronquées qui restent dans le contexte. Si vous recevez une erreur de limite de débit, Claude peut créer une réponse partielle puis réessayer en conservant le contexte précédent avec ce message partiel rempli d’erreurs. Résultat : le contexte se gonfle avec des informations inutiles et des tokens partent en fumée.
Dans le même ordre d’idées, il existe d’autres problèmes similaires. À cause de tout cela, beaucoup de développeurs se plaignent de limites atteintes bien trop vite.
Du coup, pour contrecarrer à la fois les limites officielles et ces fuites de tokens cachées, vous devez prendre certaines mesures pour que Claude Code dure plus longtemps lorsque vous construisez vos produits.
Les commandes essentielles pour économiser des tokens
La commande /clear : utilisez-la dès que vous avez terminé une tâche et que le contexte précédent ne sert plus. Par exemple, quand vous avez fini d’implémenter l’application et que vous souhaitez passer à la phase de test, vous n’avez plus besoin du contexte de développement. Réinitialisez et démarrez la tâche suivante avec une fenêtre contextuelle propre.
Si vous souhaitez conserver une partie du contexte, exécutez /compact à la place. Il résume toute l’interaction et libère de l’espace avec un résumé dans le contexte. Pourquoi ces commandes sont cruciales : chaque message envoyé par Claude inclut l’intégralité de la conversation, les invites système, vos outils et tout l’historique des conversations précédentes. À chaque nouveau message, ce volume ne cesse de croître, ce qui entraîne une fenêtre contextuelle gonflée et une utilisation plus élevée des tokens par message.
La commande /pass permet de poser une question secondaire rapide dans une fenêtre contextuelle de session distincte. Cette question secondaire ne s’ajoute pas au prochain message que vous enverriez dans le flux principal, ce qui entraîne moins de tokens par requête.
Même si la planification peut sembler une tâche gourmande en tokens au départ, démarrer vos projets avec elle est un investissement qui se rentabilise. En effet, si vous ne consacrez pas de temps à la planification, vous devrez corriger Claude plus tard lorsque sa mise en œuvre ne correspond pas à vos besoins. Dépenser des tokens dès le départ pour la planification vous évite de gaspiller beaucoup plus de tokens en corrections ultérieures.
Que faire quand Claude ne suit pas vos instructions correctement ?
Au lieu de répéter ou reformuler en gaspillant des tokens, exécutez la commande /rewind pour restaurer la conversation et le code à un point précédent, avant le message où Claude a dévié. Vous pouvez aussi appuyer deux fois sur la touche Échap pour obtenir le même résultat. L’implémentation incorrecte est supprimée de la fenêtre contextuelle et les mauvaises sorties ne sont jamais envoyées au modèle.
Structurer son projet pour réduire les tokens Claude Code
Vous avez peut-être structuré vos projets à l’aide de différents frameworks comme BEMAD, Spec Kit ou d’autres. Problème : la majorité de ces frameworks nécessitent en réalité beaucoup de tokens. Si vous les utilisez dans votre propre application, attendez-vous à ce que votre limite de tokens soit atteinte plus rapidement. Bien que ces frameworks puissent fonctionner sur les forfaits Max, ils ne tiendront certainement pas sur les forfaits Pro.
Un VPN protège votre vie privée en ligne et sécurise vos données sur les réseaux publics (Wi-Fi gratuit, hotspot, etc.). Si vous cherchez un VPN sans vous ruiner, ProtonVPN a une offre gratuite illimitée (pas de limite de data, pas de carte bancaire).
Même sans framework tiers, si vous avez utilisé la commande /init pour générer votre fichier Claude.md, il y a des problèmes.
À moins que vous n’ayez un indicateur d’exécution différent pour lancer le serveur, il n’est pas nécessaire de les ajouter. De même avec l’architecture : Claude peut lire les noms de fichiers et déduire la signification de chacun en fonction du nom, car il comprend les systèmes de fichiers et les utilise pour naviguer. Ce type d’instructions n’est donc pas réellement nécessaire, sauf dans des cas spécifiques où des orientations supplémentaires sont requises.
Plus le fichier Claude.md est court, mieux Claude se concentre sur ce qui compte vraiment
Tout ce que vous y incluez doit être applicable de manière générique à l’ensemble du projet, et non des détails spécifiques de chaque partie regroupés dans un seul fichier.
Vous devez configurer ce fichier correctement car il est chargé dans le contexte une fois à chaque session et y reste. Des informations inutiles dans la fenêtre contextuelle signifient que vous gaspillez des tokens à chaque tour, alors qu’elles n’étaient même pas nécessaires au départ.
Pour des aspects spécifiques du projet comme le schéma de base de données ou d’autres domaines où des règles différentes s’appliquent, divisez-les en documents séparés et liez-les dans le fichier Claude.md. Cela permet à Claude d’extraire progressivement uniquement les documents dont il a réellement besoin.
Créer des règles de projet spécifiques à certains parcours aide aussi Claude à rester focalisé. De cette façon, il ne dispose que des informations pertinentes dans son contexte et évite l’utilisation inutile de tokens. Séparez les fichiers de règles pour une logique spécifique à une zone afin que Claude puisse charger uniquement ce qui est requis.
Pensez aussi à utiliser vos compétences pour les flux de travail répétitifs et y ajouter des scripts et des références afin d’effectuer les tâches avec plus de précision. Les compétences chargent progressivement uniquement la partie requise, ce qui permet à Claude de rester concentré sur l’aspect pertinent de la tâche. Le regroupement avec des scripts aide à ne pas gaspiller de tokens sur des tâches déterministes qui peuvent être gérées par programme.
Vous pouvez aussi utiliser l’indicateur d’ajout d’invite système pour injecter des instructions spécifiques directement dans le prompt système. La session démarre avec ces instructions au lieu de tout mettre dans Claude.md.
Ces instructions sont temporaires et seront supprimées une fois la session terminée. Cela peut sembler ajouter au contexte, mais c’est en fait plus efficace que de mettre une instruction unique dans Claude.md : si vous l’ajoutez là, Claude la conserve en permanence et gaspille des tokens tour après tour. Grâce à l’ajout, vous fournissez les instructions exactement quand vous en avez besoin.
Choisir le bon modèle et optimiser les serveurs MCP
Vous devez également définir le niveau d’effort du modèle que vous utilisez. Si vous ne travaillez pas sur une tâche qui nécessite beaucoup de réflexion, réglez-le sur faible, car le paramètre bas enregistre des tokens.
Par défaut, il est défini sur effort automatique (le modèle décide lui-même), mais vous pouvez le modifier manuellement. Si votre tâche n’est pas très complexe, il n’est pas nécessaire d’utiliser un paramètre d’effort élevé.
D’après les benchmarks publiés par SFEIR en février 2026, passer de Opus à Sonnet sur des tâches de routine permet de réduire la consommation de tokens de 60 à 70 % sans perte notable de qualité.
Donc, si vous travaillez sur des tâches simples, passez sur Haiku. Si votre tâche nécessite un niveau de réflexion raisonnable, utilisez Sonnet. Il n’est peut-être pas aussi puissant qu’Opus, mais il reste efficace et permet d’économiser nettement plus de tokens.
Si vous avez configuré plusieurs serveurs MCP pour un projet et que vous n’en avez pas besoin d’un en particulier, désactivez-le simplement afin qu’il ne gaspille pas de tokens en injectant des informations inutiles dans la fenêtre contextuelle.
Lorsqu’on exécute des tests, ils signalent les cas réussis et échoués, et tout cela est chargé dans le contexte. Mais la préoccupation principale de Claude concerne les tests ratés, puisque ce sont eux qu’il faut corriger. Vous pouvez donc créer un hook qui utilise un script pour empêcher les cas de test passés d’entrer dans la fenêtre contextuelle, et seuls ceux qui ont échoué sont inclus.
Les réglages cachés du dossier .claude
En dehors de tout ce qui précède, vous devez effectuer certaines configurations dans votre dossier .claude pour améliorer les performances.
La première consiste à définir la désactivation de la mise en cache des invites sur false. Cela permet à Claude de mettre en cache vos préfixes les plus couramment utilisés, ce qui réduit l’utilisation des tokens. Anthropic ne vous facture pas les pièces envoyées à plusieurs reprises, vous payez uniquement pour le nouveau contenu.
Vous pouvez aussi désactiver la mémoire automatique pour l’empêcher d’ajouter du contenu à votre contexte et d’augmenter l’utilisation des tokens. La mémoire automatique est un processus en arrière-plan qui analyse vos conversations et consolide les informations utiles en fichiers de mémoire pour votre projet spécifique. La désactiver signifie qu’il ne suivra pas vos habitudes, mais qu’il enregistrera des tokens en ne s’exécutant pas en arrière-plan.
Il existe un autre indicateur appelé désactiver la tâche en arrière-plan, qui empêche les processus en arrière-plan de consommer des tokens en continu.
- Cela inclue la refactorisation,
- le nettoyage de mémoire
- et l’indexation en arrière-plan.
Pensez à désactiver la réflexion lorsqu’elle n’est pas nécessaire, car elle consomme beaucoup de contexte et gaspille énormément de tokens sur des tâches qui n’en ont même pas besoin. Attention, ceci est différent du paramètre d’effort dont nous avons discuté plus tôt. Le paramètre d’effort contrôle la quantité de raisonnement que Claude effectue dans une réponse : moins d’effort signifie moins de réflexion, mais l’ia continue de penser.
J'ai utilisé plusieurs VPN au fil des années, et NordVPN reste la référence pour le streaming et le débit (plus de 6 000 serveurs dans 111 pays). Si vous voulez un VPN qui ne ralentit pas votre connexion et débloque les catalogues Netflix étrangers sans prise de tête, c'est le choix le plus solide du marché. Et avec leur garantie 30 jours satisfait ou remboursé, vous ne prenez aucun risque.
La désactivation de la pensée, elle, désactive complètement l’étape de raisonnement interne et Claude génère simplement la réponse directement. Donc, si votre tâche ne nécessite pas de raisonnement approfondi, désactivez complètement la réflexion. Si cela nécessite un peu de raisonnement mais pas beaucoup, réduisez plutôt le niveau d’effort.
Enfin, configurez le nombre maximal de jetons de sortie sur une valeur définie. Il n’y a pas de valeur par défaut, mais limiter ce chiffre contrôle directement la quantité générée par le modèle à chaque tour.
Pour réduire les tokens Claude Code de façon durable, il n’y a pas de solution magique : c’est l’accumulation de ces micro-optimisations, des commandes de session à la structure du projet en passant par les flags cachés du dossier .claude, qui fait la différence entre une session qui tient la journée et un quota vide à midi.
